 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Similarity to Vulnerability: Key Collision Attack on LLM Semantic Caching
Jan 30, 2026Semantic caching has emerged as a pivotal technique for scaling LLM applications, widely adopted by major providers including AWS and Microsoft. By utilizing semantic embedding vectors as cache keys, this mechanism effectively minimizes latency and redundant computation for semantically similar queries. In this work, we conceptualize semantic cache keys as a form of fuzzy hashes. We demonstrate that the locality required to maximize cache hit rates fundamentally conflicts with the cryptographic avalanche effect necessary for collision resistance. Our conceptual analysis formalizes this inherent trade-off between performance (locality) and security (collision resilience), revealing that semantic caching is naturally vulnerable to key collision attacks. While prior research has focused on side-channel and privacy risks, we present the first systematic study of integrity risks arising from cache collisions. We introduce CacheAttack, an automated framework for launching black-box collision attacks. We evaluate CacheAttack in security-critical tasks and agentic workflows. It achieves a hit rate of 86\% in LLM response hijacking and can induce malicious behaviors in LLM agent, while preserving strong transferability across different embedding models. A case study on a financial agent further illustrates the real-world impact of these vulnerabilities. Finally, we discuss mitigation strategies.
CompressionAttack: Exploiting Prompt Compression as a New Attack Surface in LLM-Powered Agents
Oct 27, 2025LLM-powered agents often use prompt compression to reduce inference costs, but this introduces a new security risk. Compression modules, which are optimized for efficiency rather than safety, can be manipulated by adversarial inputs, causing semantic drift and altering LLM behavior. This work identifies prompt compression as a novel attack surface and presents CompressionAttack, the first framework to exploit it. CompressionAttack includes two strategies: HardCom, which uses discrete adversarial edits for hard compression, and SoftCom, which performs latent-space perturbations for soft compression. Experiments on multiple LLMs show up to 80% attack success and 98% preference flips, while remaining highly stealthy and transferable. Case studies in VSCode Cline and Ollama confirm real-world impact, and current defenses prove ineffective, highlighting the need for stronger protections.
On Evaluating The Performance of Watermarked Machine-Generated Texts Under Adversarial Attacks
Jul 05, 2024



Large Language Models (LLMs) excel in various applications, including text generation and complex tasks. However, the misuse of LLMs raises concerns about the authenticity and ethical implications of the content they produce, such as deepfake news, academic fraud, and copyright infringement. Watermarking techniques, which embed identifiable markers in machine-generated text, offer a promising solution to these issues by allowing for content verification and origin tracing. Unfortunately, the robustness of current LLM watermarking schemes under potential watermark removal attacks has not been comprehensively explored. In this paper, to fill this gap, we first systematically comb the mainstream watermarking schemes and removal attacks on machine-generated texts, and then we categorize them into pre-text (before text generation) and post-text (after text generation) classes so that we can conduct diversified analyses. In our experiments, we evaluate eight watermarks (five pre-text, three post-text) and twelve attacks (two pre-text, ten post-text) across 87 scenarios. Evaluation results indicate that (1) KGW and Exponential watermarks offer high text quality and watermark retention but remain vulnerable to most attacks; (2) Post-text attacks are found to be more efficient and practical than pre-text attacks; (3) Pre-text watermarks are generally more imperceptible, as they do not alter text fluency, unlike post-text watermarks; (4) Additionally, combined attack methods can significantly increase effectiveness, highlighting the need for more robust watermarking solutions. Our study underscores the vulnerabilities of current techniques and the necessity for developing more resilient schemes.
Have You Merged My Model? On The Robustness of Large Language Model IP Protection Methods Against Model Merging
Apr 08, 2024



Model merging is a promising lightweight model empowerment technique that does not rely on expensive computing devices (e.g., GPUs) or require the collection of specific training data. Instead, it involves editing different upstream model parameters to absorb their downstream task capabilities. However, uncertified model merging can infringe upon the Intellectual Property (IP) rights of the original upstream models. In this paper, we conduct the first study on the robustness of IP protection methods in model merging scenarios. We investigate two state-of-the-art IP protection techniques: Quantization Watermarking and Instructional Fingerprint, along with various advanced model merging technologies, such as Task Arithmetic, TIES-MERGING, and so on. Experimental results indicate that current Large Language Model (LLM) watermarking techniques cannot survive in the merged models, whereas model fingerprinting techniques can. Our research aims to highlight that model merging should be an indispensable consideration in the robustness assessment of model IP protection techniques, thereby promoting the healthy development of the open-source LLM community.
Tackling the Curse of Dimensionality in Large-scale Multi-agent LTL Task Planning via Poset Product
Aug 22, 2023



Linear Temporal Logic (LTL) formulas have been used to describe complex tasks for multi-agent systems, with both spatial and temporal constraints. However, since the planning complexity grows exponentially with the number of agents and the length of the task formula, existing applications are mostly limited to small artificial cases. To address this issue, a new planning algorithm is proposed for task formulas specified as sc-LTL formulas. It avoids two common bottlenecks in the model-checking-based planning methods, i.e., (i) the direct translation of the complete task formula to the associated B\"uchi automaton; and (ii) the synchronized product between the B\"uchi automaton and the transition models of all agents. In particular, each conjuncted sub-formula is first converted to the associated R-posets as an abstraction of the temporal dependencies among the subtasks. Then, an efficient algorithm is proposed to compute the product of these R-posets, which retains their dependencies and resolves potential conflicts. Furthermore, the proposed approach is applied to dynamic scenes where new tasks are generated online. It is capable of deriving the first valid plan with a polynomial time and memory complexity w.r.t. the system size and the formula length. Our method can plan for task formulas with a length of more than 60 and a system with more than 35 agents, while most existing methods fail at the formula length of 20. The proposed method is validated on large fleets of service robots in both simulation and hardware experiments.
Time Minimization and Online Synchronization for Multi-agent Systems under Collaborative Temporal Tasks
Aug 16, 2022
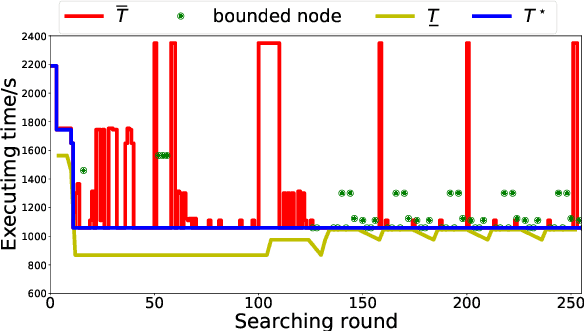
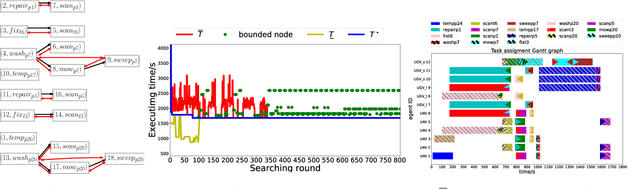
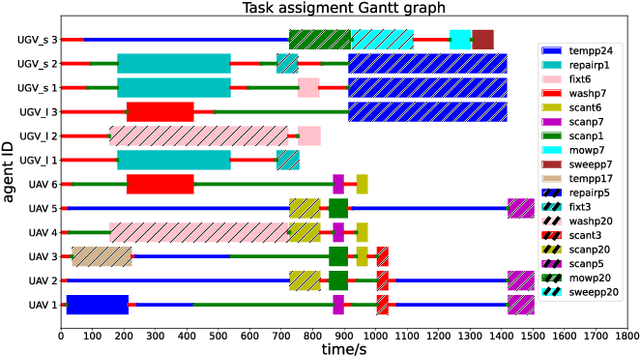
Multi-agent systems can be extremely efficient when solving a team-wide task in a concurrent manner. However, without proper synchronization, the correctness of the combined behavior is hard to guarantee, such as to follow a specific ordering of sub-tasks or to perform a simultaneous collaboration. This work addresses the minimum-time task planning problem for multi-agent systems under complex global tasks stated as Linear Temporal Logic (LTL) formulas. These tasks include the temporal and spatial requirements on both independent local actions and direct sub-team collaborations. The proposed solution is an anytime algorithm that combines the partial-ordering analysis of the underlying task automaton for task decomposition, and the branch and bound (BnB) search method for task assignment. Analyses of its soundness, completeness and optimality as the minimal completion time are provided. It is also shown that a feasible and near-optimal solution is quickly reached while the search continues within the time budget. Furthermore, to handle fluctuations in task duration and agent failures during online execution, an adaptation algorithm is proposed to synchronize execution status and re-assign unfinished subtasks dynamically to maintain correctness and optimality. Both algorithms are validated rigorously over large-scale systems via numerical simulations and hardware experiments, against several strong baselines.