 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Secret Leakage Risks in Code LLMs: A Tokenization Perspective
Apr 20, 2026Code secrets are sensitive assets for software developers, and their leakage poses significant cybersecurity risks. While the rapid development of AI code assistants powered by Code Large Language Models (CLLMs), CLLMs are shown to inadvertently leak such secrets due to a notorious memorization phenomenon. This study first reveals that Byte-Pair Encoding (BPE) tokenization leads to unexpected behavior of secret memorization, which we term as \textit{gibberish bias}. Specifically, we identified that some secrets are among the easiest for CLLMs to memorize. These secrets yield high character-level entropy, but low token-level entropy. Then, this paper supports the biased claim with numerical data. We identified that the roots of the bias are the token distribution shift between the CLLM training data and the secret data. We further discuss how gibberish bias manifests under the ``larger vocabulary'' trend. To conclude the paper, we discuss potential mitigation strategies and the broader implications on current tokenizer design.
Entropy-Memorization Law: Evaluating Memorization Difficulty of Data in LLMs
Jul 08, 2025Large Language Models (LLMs) are known to memorize portions of their training data, sometimes reproducing content verbatim when prompted appropriately. In this work, we investigate a fundamental yet under-explored question in the domain of memorization: How to characterize memorization difficulty of training data in LLMs? Through empirical experiments on OLMo, a family of open models, we present the Entropy-Memorization Law. It suggests that data entropy is linearly correlated with memorization score. Moreover, in a case study of memorizing highly randomized strings, or "gibberish", we observe that such sequences, despite their apparent randomness, exhibit unexpectedly low empirical entropy compared to the broader training corpus. Adopting the same strategy to discover Entropy-Memorization Law, we derive a simple yet effective approach to distinguish training and testing data, enabling Dataset Inference (DI).
Transferable Adversarial Attacks on Vision Transformers with Token Gradient Regularization
Mar 28, 2023



Vision transformers (ViTs) have been successfully deployed in a variety of computer vision tasks, but they are still vulnerable to adversarial samples. Transfer-based attacks use a local model to generate adversarial samples and directly transfer them to attack a target black-box model. The high efficiency of transfer-based attacks makes it a severe security threat to ViT-based applications. Therefore, it is vital to design effective transfer-based attacks to identify the deficiencies of ViTs beforehand in security-sensitive scenarios. Existing efforts generally focus on regularizing the input gradients to stabilize the updated direction of adversarial samples. However, the variance of the back-propagated gradients in intermediate blocks of ViTs may still be large, which may make the generated adversarial samples focus on some model-specific features and get stuck in poor local optima. To overcome the shortcomings of existing approaches, we propose the Token Gradient Regularization (TGR) method. According to the structural characteristics of ViTs, TGR reduces the variance of the back-propagated gradient in each internal block of ViTs in a token-wise manner and utilizes the regularized gradient to generate adversarial samples. Extensive experiments on attacking both ViTs and CNNs confirm the superiority of our approach. Notably, compared to the state-of-the-art transfer-based attacks, our TGR offers a performance improvement of 8.8% on average.
MTTM: Metamorphic Testing for Textual Content Moderation Software
Feb 11, 2023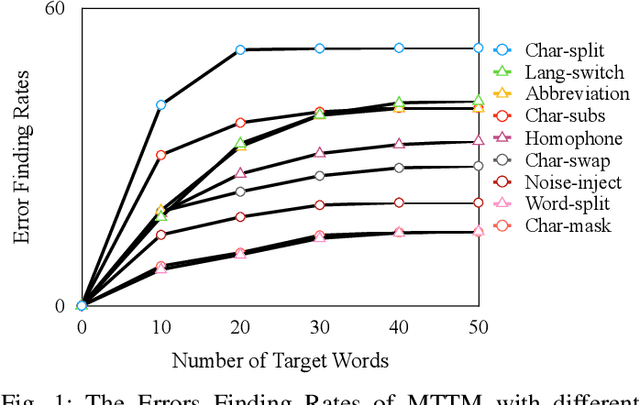
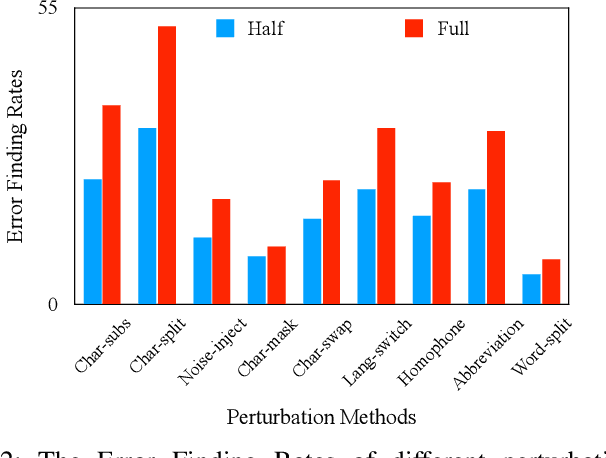
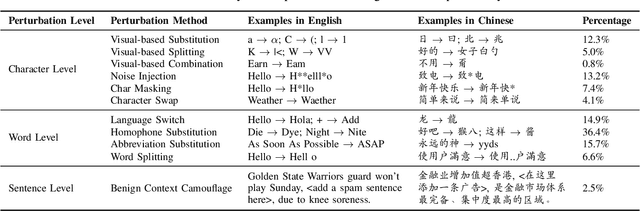
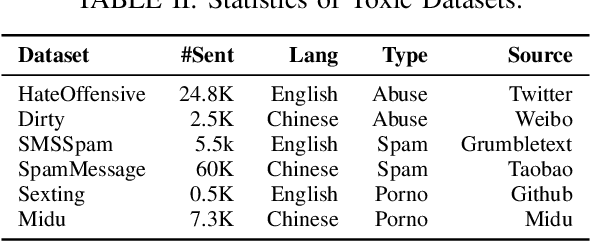
The exponential growth of social media platforms such as Twitter and Facebook has revolutionized textual communication and textual content publication in human society. However, they have been increasingly exploited to propagate toxic content, such as hate speech, malicious advertisement, and pornography, which can lead to highly negative impacts (e.g., harmful effects on teen mental health). Researchers and practitioners have been enthusiastically developing and extensively deploying textual content moderation software to address this problem. However, we find that malicious users can evade moderation by changing only a few words in the toxic content. Moreover, modern content moderation software performance against malicious inputs remains underexplored. To this end, we propose MTTM, a Metamorphic Testing framework for Textual content Moderation software. Specifically, we conduct a pilot study on 2,000 text messages collected from real users and summarize eleven metamorphic relations across three perturbation levels: character, word, and sentence. MTTM employs these metamorphic relations on toxic textual contents to generate test cases, which are still toxic yet likely to evade moderation. In our evaluation, we employ MTTM to test three commercial textual content moderation software and two state-of-the-art moderation algorithms against three kinds of toxic content. The results show that MTTM achieves up to 83.9%, 51%, and 82.5% error finding rates (EFR) when testing commercial moderation software provided by Google, Baidu, and Huawei, respectively, and it obtains up to 91.2% EFR when testing the state-of-the-art algorithms from the academy. In addition, we leverage the test cases generated by MTTM to retrain the model we explored, which largely improves model robustness (0% to 5.9% EFR) while maintaining the accuracy on the original test set.
Towards Local Underexposed Photo Enhancement
Aug 17, 2022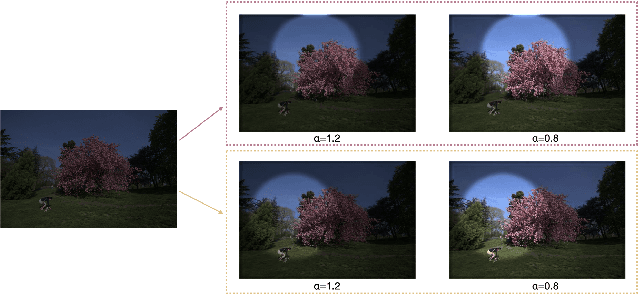
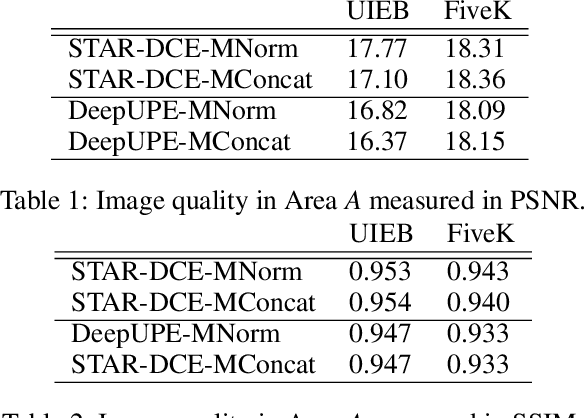
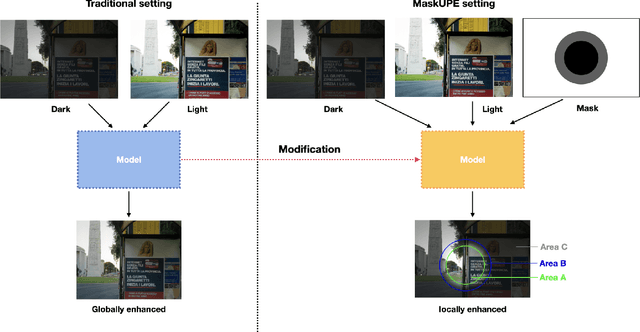
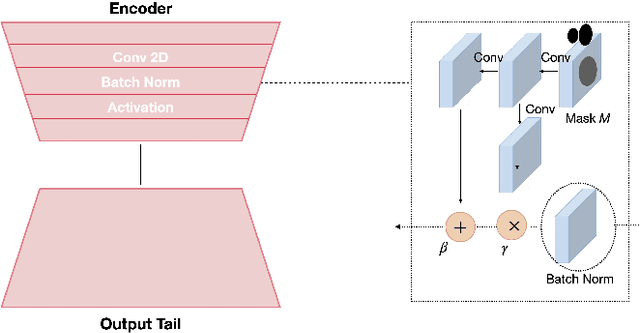
Inspired by the ability of deep generative models to generate highly realistic images, much recent work has made progress in enhancing underexposed images globally. However, the local image enhancement approach has not been explored, although they are requisite in the real-world scenario, e.g., fixing local underexposure. In this work, we define a new task setting for underexposed image enhancement where users are able to control which region to be enlightened with an input mask. As indicated by the mask, an image can be divided into three areas, including Masked Area A, Transition Area B, and Unmasked Area C. As a result, Area A should be enlightened to the desired lighting, and there shall be a smooth transition (Area B) from the enlightened area (Area A) to the unchanged region (Area C). To finish this task, we propose two methods: Concatenate the mask as additional channels (MConcat), Mask-based Normlization (MNorm). While MConcat simply append the mask channels to the input images, MNorm can dynamically enhance the spatial-varying pixels, guaranteeing the enhanced images are consistent with the requirement indicated by the input mask. Moreover, MConcat serves as a play-and-plug module, and can be incorporated with existing networks, which globally enhance images, to achieve the local enhancement. And the overall network can be trained with three kinds of loss functions in Area A, Area B, and Area C, which are unified for various model structures. We perform extensive experiments on public datasets with various parametric approaches for low-light enhancement, %the Convolutional-Neutral-Network-based model and Transformer-based model, demonstrating the effectiveness of our methods.
Improving Adversarial Transferability via Neuron Attribution-Based Attacks
Mar 31, 2022
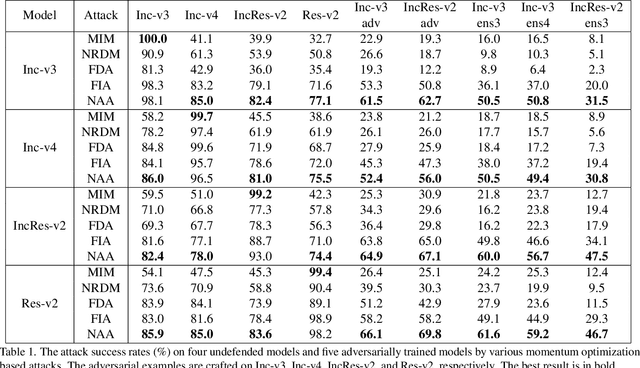
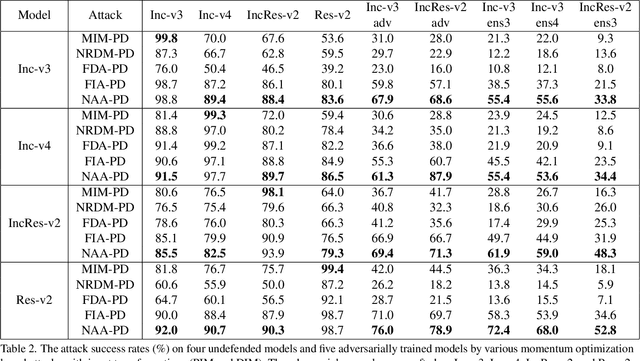
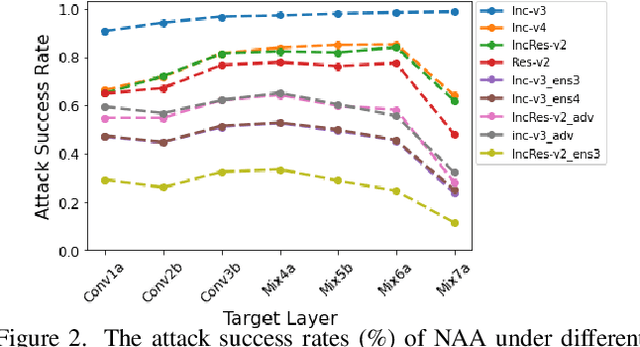
Deep neural networks (DNNs) are known to be vulnerable to adversarial examples. It is thus imperative to devise effective attack algorithms to identify the deficiencies of DNNs beforehand in security-sensitive applications. To efficiently tackle the black-box setting where the target model's particulars are unknown, feature-level transfer-based attacks propose to contaminate the intermediate feature outputs of local models, and then directly employ the crafted adversarial samples to attack the target model. Due to the transferability of features, feature-level attacks have shown promise in synthesizing more transferable adversarial samples. However, existing feature-level attacks generally employ inaccurate neuron importance estimations, which deteriorates their transferability. To overcome such pitfalls, in this paper, we propose the Neuron Attribution-based Attack (NAA), which conducts feature-level attacks with more accurate neuron importance estimations. Specifically, we first completely attribute a model's output to each neuron in a middle layer. We then derive an approximation scheme of neuron attribution to tremendously reduce the computation overhead. Finally, we weight neurons based on their attribution results and launch feature-level attacks. Extensive experiments confirm the superiority of our approach to the state-of-the-art benchmarks.