 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAEON: A Method for Automatic Evaluation of NLP Test Cases
Paper and Code



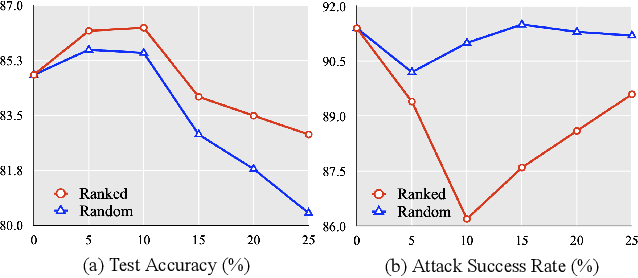
Due to the labor-intensive nature of manual test oracle construction, various automated testing techniques have been proposed to enhance the reliability of Natural Language Processing (NLP) software. In theory, these techniques mutate an existing test case (e.g., a sentence with its label) and assume the generated one preserves an equivalent or similar semantic meaning and thus, the same label. However, in practice, many of the generated test cases fail to preserve similar semantic meaning and are unnatural (e.g., grammar errors), which leads to a high false alarm rate and unnatural test cases. Our evaluation study finds that 44% of the test cases generated by the state-of-the-art (SOTA) approaches are false alarms. These test cases require extensive manual checking effort, and instead of improving NLP software, they can even degrade NLP software when utilized in model training. To address this problem, we propose AEON for Automatic Evaluation Of NLP test cases. For each generated test case, it outputs scores based on semantic similarity and language naturalness. We employ AEON to evaluate test cases generated by four popular testing techniques on five datasets across three typical NLP tasks. The results show that AEON aligns the best with human judgment. In particular, AEON achieves the best average precision in detecting semantic inconsistent test cases, outperforming the best baseline metric by 10%. In addition, AEON also has the highest average precision of finding unnatural test cases, surpassing the baselines by more than 15%. Moreover, model training with test cases prioritized by AEON leads to models that are more accurate and robust, demonstrating AEON's potential in improving NLP software.