 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Incident Aggregation for Large-Scale Online Service Systems
Aug 27, 2021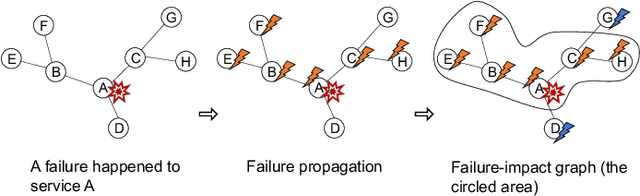
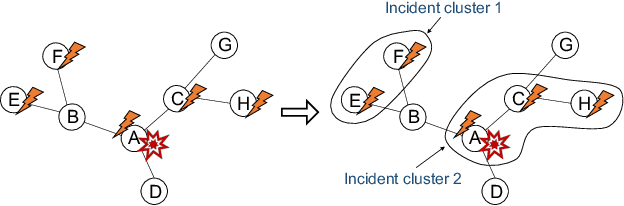
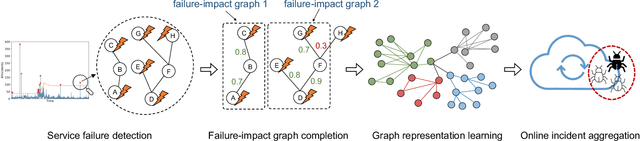
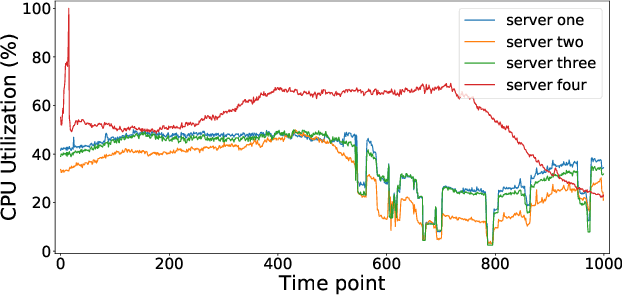
As online service systems continue to grow in terms of complexity and volume, how service incidents are managed will significantly impact company revenue and user trust. Due to the cascading effect, cloud failures often come with an overwhelming number of incidents from dependent services and devices. To pursue efficient incident management, related incidents should be quickly aggregated to narrow down the problem scope. To this end, in this paper, we propose GRLIA, an incident aggregation framework based on graph representation learning over the cascading graph of cloud failures. A representation vector is learned for each unique type of incident in an unsupervised and unified manner, which is able to simultaneously encode the topological and temporal correlations among incidents. Thus, it can be easily employed for online incident aggregation. In particular, to learn the correlations more accurately, we try to recover the complete scope of failures' cascading impact by leveraging fine-grained system monitoring data, i.e., Key Performance Indicators (KPIs). The proposed framework is evaluated with real-world incident data collected from a large-scale online service system of Huawei Cloud. The experimental results demonstrate that GRLIA is effective and outperforms existing methods. Furthermore, our framework has been successfully deployed in industrial practice.