 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Mixing in Reasoning Language Models: Patterns, Impact, and Internal Causes
May 20, 2025Reasoning language models (RLMs) excel at complex tasks by leveraging a chain-of-thought process to generate structured intermediate steps. However, language mixing, i.e., reasoning steps containing tokens from languages other than the prompt, has been observed in their outputs and shown to affect performance, though its impact remains debated. We present the first systematic study of language mixing in RLMs, examining its patterns, impact, and internal causes across 15 languages, 7 task difficulty levels, and 18 subject areas, and show how all three factors influence language mixing. Moreover, we demonstrate that the choice of reasoning language significantly affects performance: forcing models to reason in Latin or Han scripts via constrained decoding notably improves accuracy. Finally, we show that the script composition of reasoning traces closely aligns with that of the model's internal representations, indicating that language mixing reflects latent processing preferences in RLMs. Our findings provide actionable insights for optimizing multilingual reasoning and open new directions for controlling reasoning languages to build more interpretable and adaptable RLMs.
Lost in Multilinguality: Dissecting Cross-lingual Factual Inconsistency in Transformer Language Models
Apr 05, 2025



Multilingual language models (MLMs) store factual knowledge across languages but often struggle to provide consistent responses to semantically equivalent prompts in different languages. While previous studies point out this cross-lingual inconsistency issue, the underlying causes remain unexplored. In this work, we use mechanistic interpretability methods to investigate cross-lingual inconsistencies in MLMs. We find that MLMs encode knowledge in a language-independent concept space through most layers, and only transition to language-specific spaces in the final layers. Failures during the language transition often result in incorrect predictions in the target language, even when the answers are correct in other languages. To mitigate this inconsistency issue, we propose a linear shortcut method that bypasses computations in the final layers, enhancing both prediction accuracy and cross-lingual consistency. Our findings shed light on the internal mechanisms of MLMs and provide a lightweight, effective strategy for producing more consistent factual outputs.
Bring Your Own Knowledge: A Survey of Methods for LLM Knowledge Expansion
Feb 18, 2025Adapting large language models (LLMs) to new and diverse knowledge is essential for their lasting effectiveness in real-world applications. This survey provides an overview of state-of-the-art methods for expanding the knowledge of LLMs, focusing on integrating various knowledge types, including factual information, domain expertise, language proficiency, and user preferences. We explore techniques, such as continual learning, model editing, and retrieval-based explicit adaptation, while discussing challenges like knowledge consistency and scalability. Designed as a guide for researchers and practitioners, this survey sheds light on opportunities for advancing LLMs as adaptable and robust knowledge systems.
Better Call SAUL: Fluent and Consistent Language Model Editing with Generation Regularization
Oct 03, 2024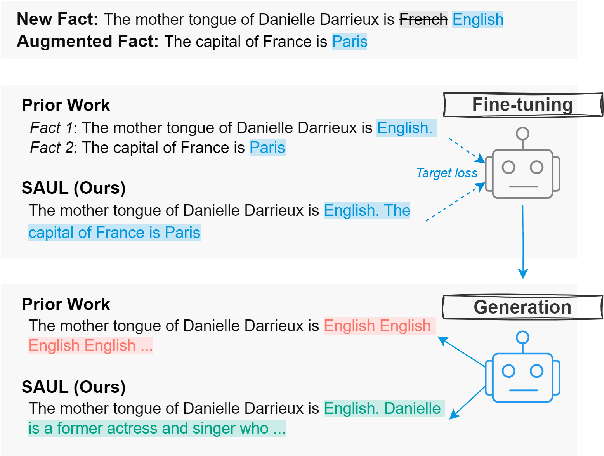
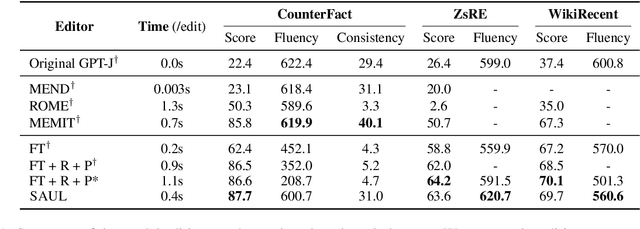

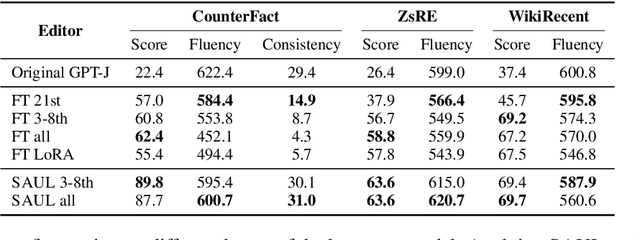
To ensure large language models contain up-to-date knowledge, they need to be updated regularly. However, model editing is challenging as it might also affect knowledge that is unrelated to the new data. State-of-the-art methods identify parameters associated with specific knowledge and then modify them via direct weight updates. However, these locate-and-edit methods suffer from heavy computational overhead and lack theoretical validation. In contrast, directly fine-tuning the model on requested edits affects the model's behavior on unrelated knowledge, and significantly damages the model's generation fluency and consistency. To address these challenges, we propose SAUL, a streamlined model editing method that uses sentence concatenation with augmented random facts for generation regularization. Evaluations on three model editing benchmarks show that SAUL is a practical and reliable solution for model editing outperforming state-of-the-art methods while maintaining generation quality and reducing computational overhead.
Learn it or Leave it: Module Composition and Pruning for Continual Learning
Jun 26, 2024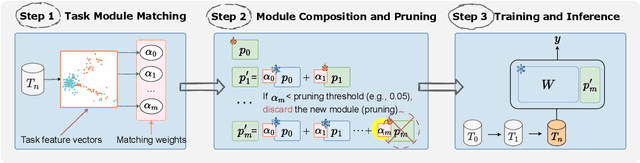
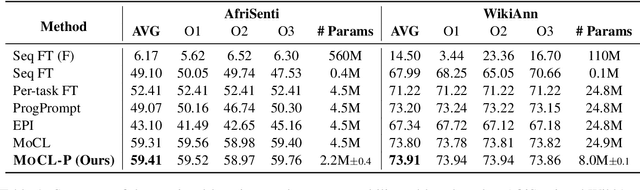
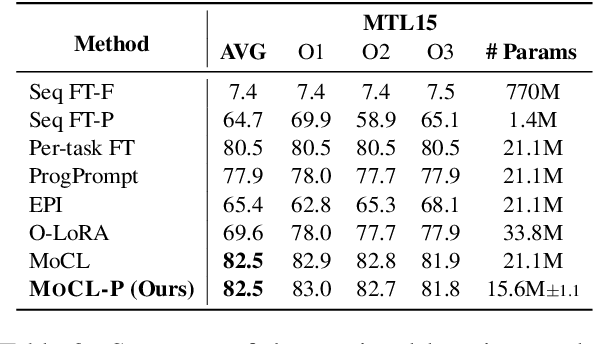
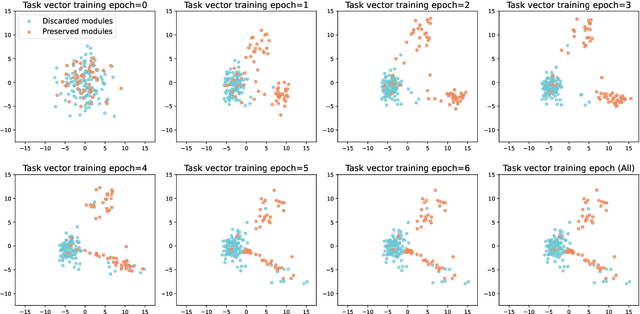
In real-world environments, continual learning is essential for machine learning models, as they need to acquire new knowledge incrementally without forgetting what they have already learned. While pretrained language models have shown impressive capabilities on various static tasks, applying them to continual learning poses significant challenges, including avoiding catastrophic forgetting, facilitating knowledge transfer, and maintaining parameter efficiency. In this paper, we introduce MoCL-P, a novel lightweight continual learning method that addresses these challenges simultaneously. Unlike traditional approaches that continuously expand parameters for newly arriving tasks, MoCL-P integrates task representation-guided module composition with adaptive pruning, effectively balancing knowledge integration and computational overhead. Our evaluation across three continual learning benchmarks with up to 176 tasks shows that MoCL-P achieves state-of-the-art performance and improves parameter efficiency by up to three times, demonstrating its potential for practical applications where resource requirements are constrained.
Discourse-Aware In-Context Learning for Temporal Expression Normalization
Apr 11, 2024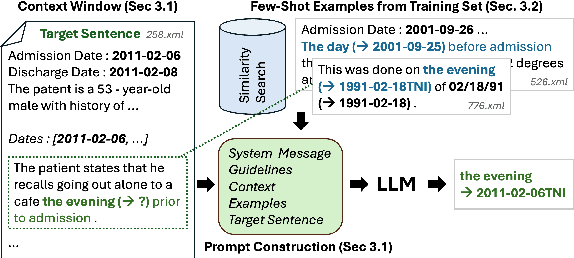



Temporal expression (TE) normalization is a well-studied problem. However, the predominately used rule-based systems are highly restricted to specific settings, and upcoming machine learning approaches suffer from a lack of labeled data. In this work, we explore the feasibility of proprietary and open-source large language models (LLMs) for TE normalization using in-context learning to inject task, document, and example information into the model. We explore various sample selection strategies to retrieve the most relevant set of examples. By using a window-based prompt design approach, we can perform TE normalization across sentences, while leveraging the LLM knowledge without training the model. Our experiments show competitive results to models designed for this task. In particular, our method achieves large performance improvements for non-standard settings by dynamically including relevant examples during inference.
Rehearsal-Free Modular and Compositional Continual Learning for Language Models
Mar 31, 2024Continual learning aims at incrementally acquiring new knowledge while not forgetting existing knowledge. To overcome catastrophic forgetting, methods are either rehearsal-based, i.e., store data examples from previous tasks for data replay, or isolate parameters dedicated to each task. However, rehearsal-based methods raise privacy and memory issues, and parameter-isolation continual learning does not consider interaction between tasks, thus hindering knowledge transfer. In this work, we propose MoCL, a rehearsal-free Modular and Compositional Continual Learning framework which continually adds new modules to language models and composes them with existing modules. Experiments on various benchmarks show that MoCL outperforms state of the art and effectively facilitates knowledge transfer.
GradSim: Gradient-Based Language Grouping for Effective Multilingual Training
Oct 23, 2023Most languages of the world pose low-resource challenges to natural language processing models. With multilingual training, knowledge can be shared among languages. However, not all languages positively influence each other and it is an open research question how to select the most suitable set of languages for multilingual training and avoid negative interference among languages whose characteristics or data distributions are not compatible. In this paper, we propose GradSim, a language grouping method based on gradient similarity. Our experiments on three diverse multilingual benchmark datasets show that it leads to the largest performance gains compared to other similarity measures and it is better correlated with cross-lingual model performance. As a result, we set the new state of the art on AfriSenti, a benchmark dataset for sentiment analysis on low-resource African languages. In our extensive analysis, we further reveal that besides linguistic features, the topics of the datasets play an important role for language grouping and that lower layers of transformer models encode language-specific features while higher layers capture task-specific information.
TADA: Efficient Task-Agnostic Domain Adaptation for Transformers
May 22, 2023


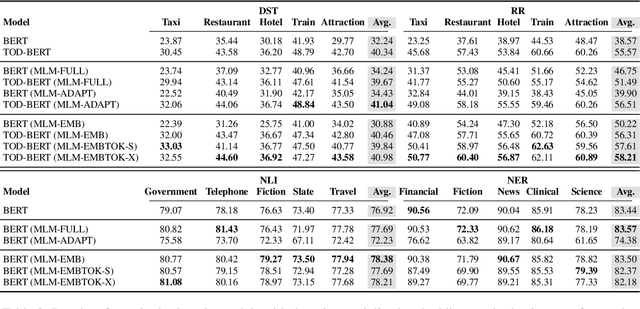
Intermediate training of pre-trained transformer-based language models on domain-specific data leads to substantial gains for downstream tasks. To increase efficiency and prevent catastrophic forgetting alleviated from full domain-adaptive pre-training, approaches such as adapters have been developed. However, these require additional parameters for each layer, and are criticized for their limited expressiveness. In this work, we introduce TADA, a novel task-agnostic domain adaptation method which is modular, parameter-efficient, and thus, data-efficient. Within TADA, we retrain the embeddings to learn domain-aware input representations and tokenizers for the transformer encoder, while freezing all other parameters of the model. Then, task-specific fine-tuning is performed. We further conduct experiments with meta-embeddings and newly introduced meta-tokenizers, resulting in one model per task in multi-domain use cases. Our broad evaluation in 4 downstream tasks for 14 domains across single- and multi-domain setups and high- and low-resource scenarios reveals that TADA is an effective and efficient alternative to full domain-adaptive pre-training and adapters for domain adaptation, while not introducing additional parameters or complex training steps.
NLNDE at SemEval-2023 Task 12: Adaptive Pretraining and Source Language Selection for Low-Resource Multilingual Sentiment Analysis
Apr 28, 2023



This paper describes our system developed for the SemEval-2023 Task 12 "Sentiment Analysis for Low-resource African Languages using Twitter Dataset". Sentiment analysis is one of the most widely studied applications in natural language processing. However, most prior work still focuses on a small number of high-resource languages. Building reliable sentiment analysis systems for low-resource languages remains challenging, due to the limited training data in this task. In this work, we propose to leverage language-adaptive and task-adaptive pretraining on African texts and study transfer learning with source language selection on top of an African language-centric pretrained language model. Our key findings are: (1) Adapting the pretrained model to the target language and task using a small yet relevant corpus improves performance remarkably by more than 10 F1 score points. (2) Selecting source languages with positive transfer gains during training can avoid harmful interference from dissimilar languages, leading to better results in multilingual and cross-lingual settings. In the shared task, our system wins 8 out of 15 tracks and, in particular, performs best in the multilingual evaluation.