 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of extended object tracking with multi-modal sensors in indoor environment
Nov 27, 2024

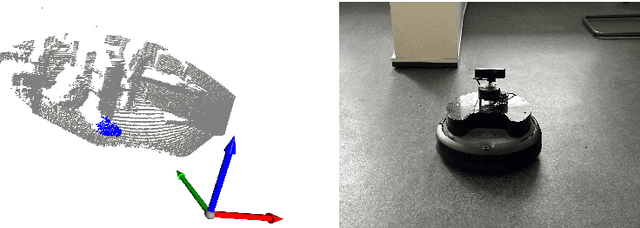

This paper presents a preliminary study of an efficient object tracking approach, comparing the performance of two different 3D point cloud sensory sources: LiDAR and stereo cameras, which have significant price differences. In this preliminary work, we focus on single object tracking. We first developed a fast heuristic object detector that utilizes prior information about the environment and target. The resulting target points are subsequently fed into an extended object tracking framework, where the target shape is parameterized using a star-convex hypersurface model. Experimental results show that our object tracking method using a stereo camera achieves performance similar to that of a LiDAR sensor, with a cost difference of more than tenfold.
Exploring the Practicality of Federated Learning: A Survey Towards the Communication Perspective
May 30, 2024Federated Learning (FL) is a promising paradigm that offers significant advancements in privacy-preserving, decentralized machine learning by enabling collaborative training of models across distributed devices without centralizing data. However, the practical deployment of FL systems faces a significant bottleneck: the communication overhead caused by frequently exchanging large model updates between numerous devices and a central server. This communication inefficiency can hinder training speed, model performance, and the overall feasibility of real-world FL applications. In this survey, we investigate various strategies and advancements made in communication-efficient FL, highlighting their impact and potential to overcome the communication challenges inherent in FL systems. Specifically, we define measures for communication efficiency, analyze sources of communication inefficiency in FL systems, and provide a taxonomy and comprehensive review of state-of-the-art communication-efficient FL methods. Additionally, we discuss promising future research directions for enhancing the communication efficiency of FL systems. By addressing the communication bottleneck, FL can be effectively applied and enable scalable and practical deployment across diverse applications that require privacy-preserving, decentralized machine learning, such as IoT, healthcare, or finance.
VisionKG: Unleashing the Power of Visual Datasets via Knowledge Graph
Sep 24, 2023



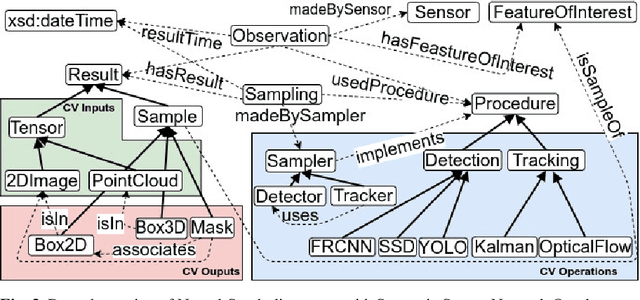
The availability of vast amounts of visual data with heterogeneous features is a key factor for developing, testing, and benchmarking of new computer vision (CV) algorithms and architectures. Most visual datasets are created and curated for specific tasks or with limited image data distribution for very specific situations, and there is no unified approach to manage and access them across diverse sources, tasks, and taxonomies. This not only creates unnecessary overheads when building robust visual recognition systems, but also introduces biases into learning systems and limits the capabilities of data-centric AI. To address these problems, we propose the Vision Knowledge Graph (VisionKG), a novel resource that interlinks, organizes and manages visual datasets via knowledge graphs and Semantic Web technologies. It can serve as a unified framework facilitating simple access and querying of state-of-the-art visual datasets, regardless of their heterogeneous formats and taxonomies. One of the key differences between our approach and existing methods is that ours is knowledge-based rather than metadatabased. It enhances the enrichment of the semantics at both image and instance levels and offers various data retrieval and exploratory services via SPARQL. VisionKG currently contains 519 million RDF triples that describe approximately 40 million entities, and are accessible at https://vision.semkg.org and through APIs. With the integration of 30 datasets and four popular CV tasks, we demonstrate its usefulness across various scenarios when working with CV pipelines.
An Empirical Study of Federated Learning on IoT-Edge Devices: Resource Allocation and Heterogeneity
May 31, 2023
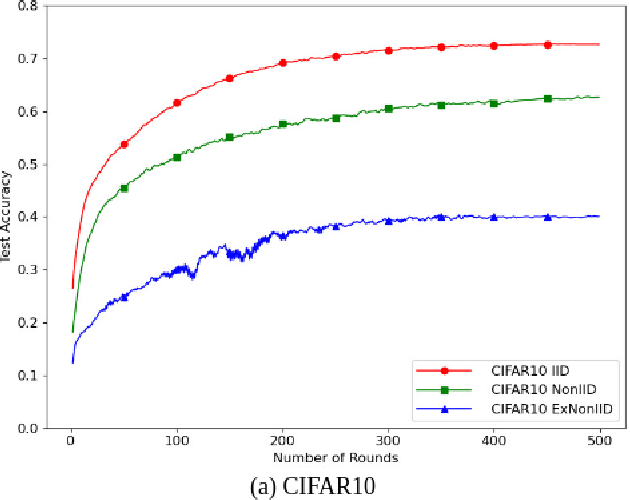


Nowadays, billions of phones, IoT and edge devices around the world generate data continuously, enabling many Machine Learning (ML)-based products and applications. However, due to increasing privacy concerns and regulations, these data tend to reside on devices (clients) instead of being centralized for performing traditional ML model training. Federated Learning (FL) is a distributed approach in which a single server and multiple clients collaboratively build an ML model without moving data away from clients. Whereas existing studies on FL have their own experimental evaluations, most experiments were conducted using a simulation setting or a small-scale testbed. This might limit the understanding of FL implementation in realistic environments. In this empirical study, we systematically conduct extensive experiments on a large network of IoT and edge devices (called IoT-Edge devices) to present FL real-world characteristics, including learning performance and operation (computation and communication) costs. Moreover, we mainly concentrate on heterogeneous scenarios, which is the most challenging issue of FL. By investigating the feasibility of on-device implementation, our study provides valuable insights for researchers and practitioners, promoting the practicality of FL and assisting in improving the current design of real FL systems.
CQELS 2.0: Towards A Unified Framework for Semantic Stream Fusion
Feb 15, 2022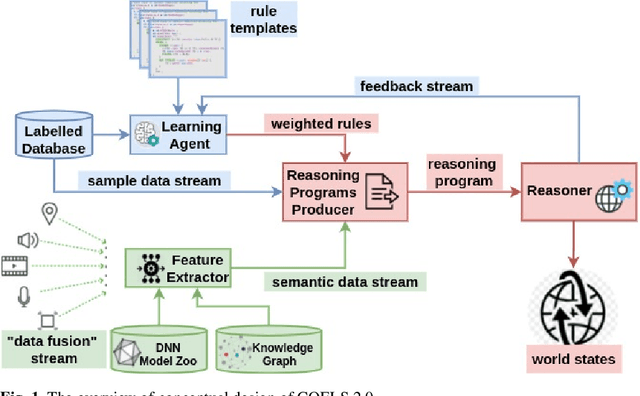
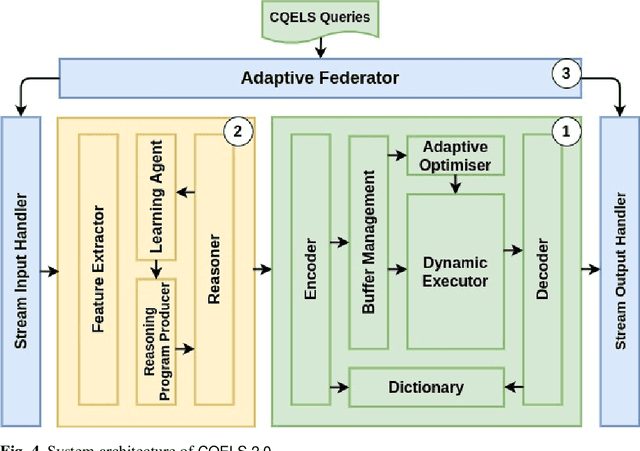
We present CQELS 2.0, the second version of Continuous Query Evaluation over Linked Streams. CQELS 2.0 is a platform-agnostic federated execution framework towards semantic stream fusion. In this version, we introduce a novel neural-symbolic stream reasoning component that enables specifying deep neural network (DNN) based data fusion pipelines via logic rules with learnable probabilistic degrees as weights. As a platform-agnostic framework, CQELS 2.0 can be implemented for devices with different hardware architectures (from embedded devices to cloud infrastructures). Moreover, this version also includes an adaptive federator that allows CQELS instances on different nodes in a network to coordinate their resources to distribute processing pipelines by delegating partial workloads to their peers via subscribing continuous queries
SemRob: Towards Semantic Stream Reasoning for Robotic Operating Systems
Jan 27, 2022



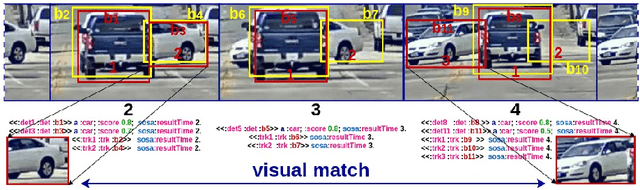
Stream processing and reasoning is getting considerable attention in various application domains such as IoT, Industry IoT and Smart Cities. In parallel, reasoning and knowledge-based features have attracted research into many areas of robotics, such as robotic mapping, perception and interaction. To this end, the Semantic Stream Reasoning (SSR) framework can unify the representations of symbolic/semantic streams with deep neural networks, to integrate high-dimensional data streams, such as video streams and LiDAR point clouds, with traditional graph or relational stream data. As such, this positioning and system paper will outline our approach to build a platform to facilitate semantic stream reasoning capabilities on a robotic operating system called SemRob.
Fantastic Data and How to Query Them
Jan 13, 2022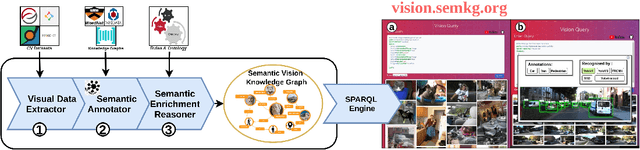
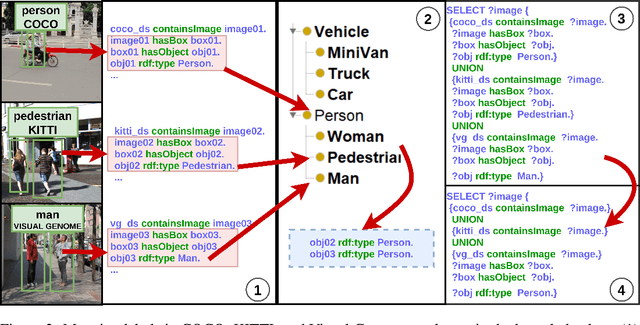
It is commonly acknowledged that the availability of the huge amount of (training) data is one of the most important factors for many recent advances in Artificial Intelligence (AI). However, datasets are often designed for specific tasks in narrow AI sub areas and there is no unified way to manage and access them. This not only creates unnecessary overheads when training or deploying Machine Learning models but also limits the understanding of the data, which is very important for data-centric AI. In this paper, we present our vision about a unified framework for different datasets so that they can be integrated and queried easily, e.g., using standard query languages. We demonstrate this in our ongoing work to create a framework for datasets in Computer Vision and show its advantages in different scenarios. Our demonstration is available at https://vision.semkg.org.