 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimSMoE: Solving Representational Collapse via Similarity Measure
Paper and Code
Jun 22, 2024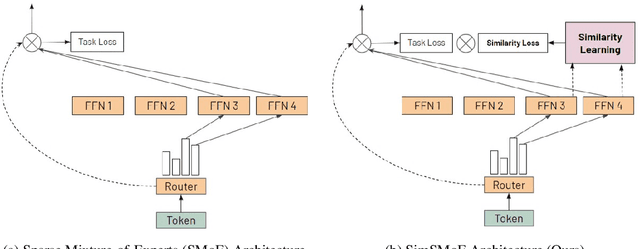
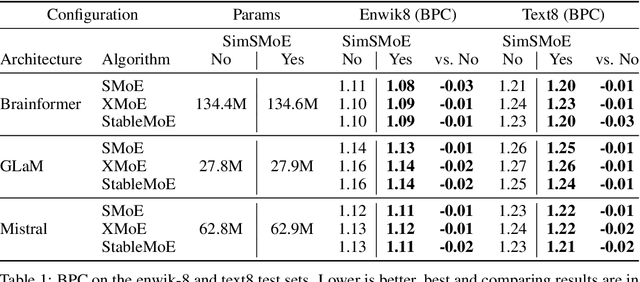
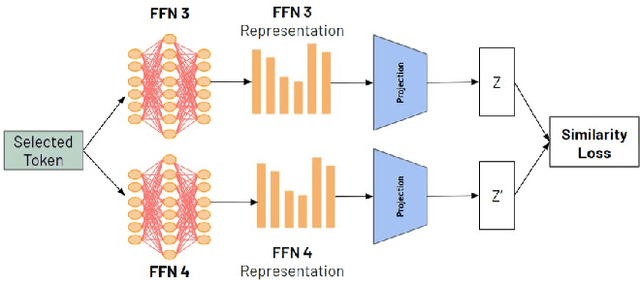
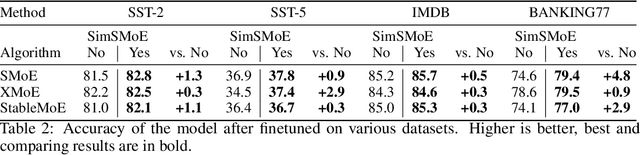
Sparse mixture of experts (SMoE) have emerged as an effective approach for scaling large language models while keeping a constant computational cost. Regardless of several notable successes of SMoE, effective training such architecture remains elusive due to the representation collapse problem, which in turn harms model performance and causes parameter redundancy. In this work, we present Similarity-based Sparse Mixture of Experts (SimSMoE), a novel similarity of neural network algorithm, that guarantees a solution to address the representation collapse issue between experts given a fixed FLOPs budget. We conduct extensive empirical evaluations on three large language models for both Pre-training and Fine-tuning tasks to illustrate the efficacy, robustness, and scalability of our method. The results demonstrate that SimSMoE significantly enhances existing routing policy and outperforms other SMoE training methods in performance for the tasks.