 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibRefine: Deep Learning-Based Online Automatic Targetless LiDAR-Camera Calibration with Iterative and Attention-Driven Post-Refinement
Feb 26, 2025Accurate multi-sensor calibration is essential for deploying robust perception systems in applications such as autonomous driving, robotics, and intelligent transportation. Existing LiDAR-camera calibration methods often rely on manually placed targets, preliminary parameter estimates, or intensive data preprocessing, limiting their scalability and adaptability in real-world settings. In this work, we propose a fully automatic, targetless, and online calibration framework, CalibRefine, which directly processes raw LiDAR point clouds and camera images. Our approach is divided into four stages: (1) a Common Feature Discriminator that trains on automatically detected objects--using relative positions, appearance embeddings, and semantic classes--to generate reliable LiDAR-camera correspondences, (2) a coarse homography-based calibration, (3) an iterative refinement to incrementally improve alignment as additional data frames become available, and (4) an attention-based refinement that addresses non-planar distortions by leveraging a Vision Transformer and cross-attention mechanisms. Through extensive experiments on two urban traffic datasets, we show that CalibRefine delivers high-precision calibration results with minimal human involvement, outperforming state-of-the-art targetless methods and remaining competitive with, or surpassing, manually tuned baselines. Our findings highlight how robust object-level feature matching, together with iterative and self-supervised attention-based adjustments, enables consistent sensor fusion in complex, real-world conditions without requiring ground-truth calibration matrices or elaborate data preprocessing.
A Review on Longitudinal Car-Following Model
Apr 14, 2023



The car-following (CF) model is the core component for traffic simulations and has been built-in in many production vehicles with Advanced Driving Assistance Systems (ADAS). Research of CF behavior allows us to identify the sources of different macro phenomena induced by the basic process of pairwise vehicle interaction. The CF behavior and control model encompasses various fields, such as traffic engineering, physics, cognitive science, machine learning, and reinforcement learning. This paper provides a comprehensive survey highlighting differences, complementarities, and overlaps among various CF models according to their underlying logic and principles. We reviewed representative algorithms, ranging from the theory-based kinematic models, stimulus-response models, and cruise control models to data-driven Behavior Cloning (BC) and Imitation Learning (IL) and outlined their strengths and limitations. This review categorizes CF models that are conceptualized in varying principles and summarize the vast literature with a holistic framework.
Multimodal Gaussian Mixture Model for Realtime Roadside LiDAR Object Detection
Apr 20, 2022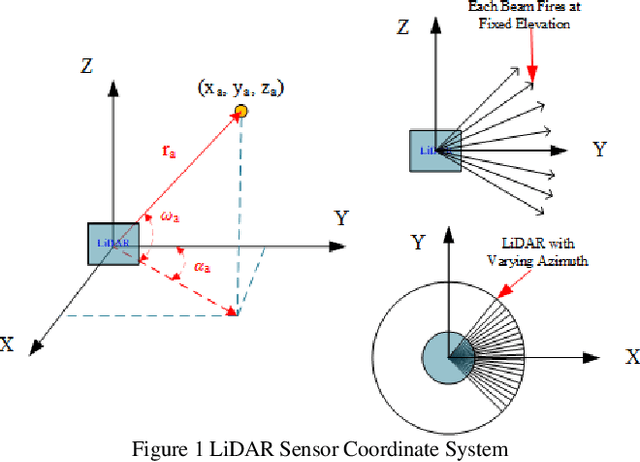
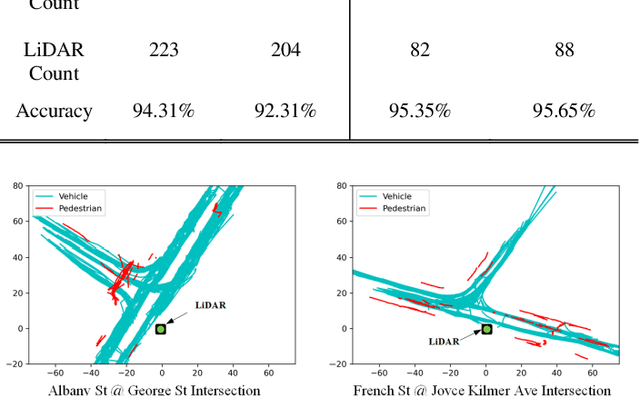
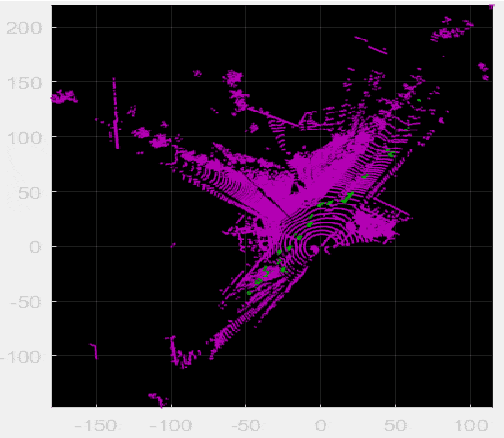
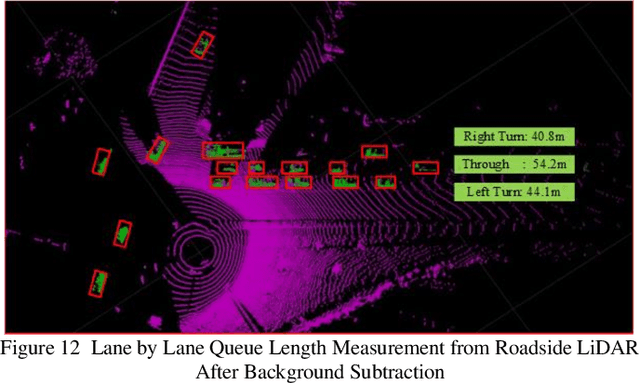
Background modeling is widely used for intelligent surveillance systems to detect the moving targets by subtracting the static background components. Most roadside LiDAR object detection methods filter out foreground points by comparing new points to pre-trained background references based on descriptive statistics over many frames (e.g., voxel density, slopes, maximum distance). These solutions are not efficient under heavy traffic, and parameter values are hard to transfer from one scenario to another. In early studies, the video-based background modeling methods were considered not suitable for roadside LiDAR surveillance systems due to the sparse and unstructured point clouds data. In this paper, the raw LiDAR data were transformed into a multi-dimensional tensor structure based on the elevation and azimuth value of each LiDAR point. With this high-order data representation, we break the barrier to allow the efficient Gaussian Mixture Model (GMM) method for roadside LiDAR background modeling. The probabilistic GMM is built with superior agility and real-time capability. The proposed Method was compared against two state-of-the-art roadside LiDAR background models and evaluated based on point level, object level, and path level, demonstrating better robustness under heavy traffic and challenging weather. This multimodal GMM method is capable of handling dynamic backgrounds with noisy measurements and substantially enhances the infrastructure-based LiDAR object detection, whereby various 3D modeling for smart city applications could be created
Roadside Lidar Vehicle Detection and Tracking Using Range And Intensity Background Subtraction
Jan 14, 2022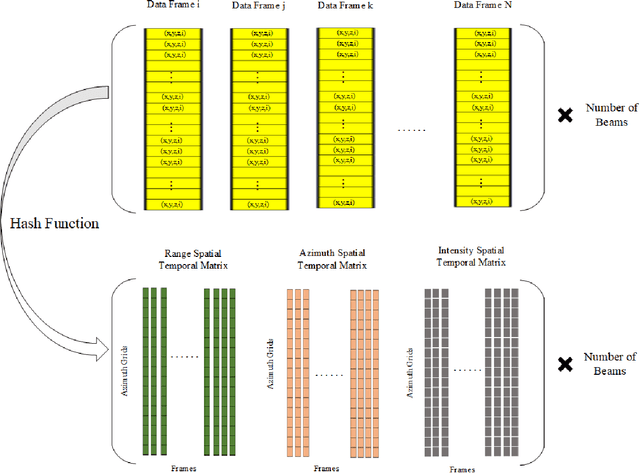

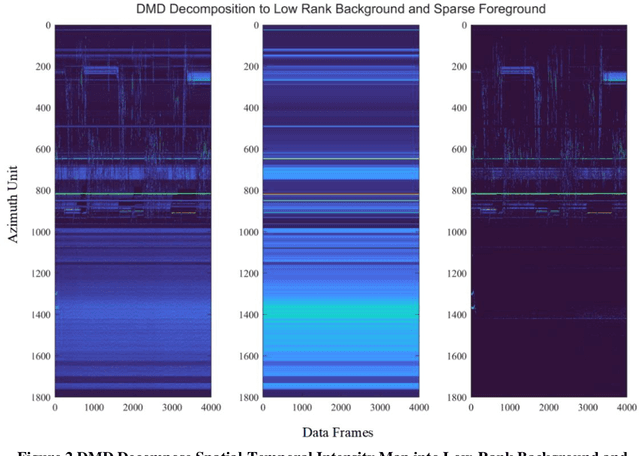
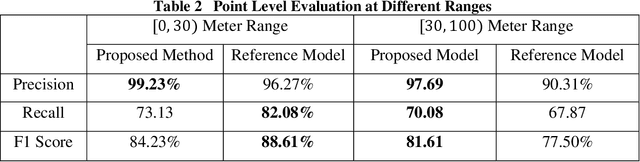
In this paper, we present the solution of roadside LiDAR object detection using a combination of two unsupervised learning algorithms. The 3D point clouds data are firstly converted into spherical coordinates and filled into the azimuth grid matrix using a hash function. After that, the raw LiDAR data were rearranged into spatial-temporal data structures to store the information of range, azimuth, and intensity. Dynamic Mode Decomposition method is applied for decomposing the point cloud data into low-rank backgrounds and sparse foregrounds based on intensity channel pattern recognition. The Triangle Algorithm automatically finds the dividing value to separate the moving targets from static background according to range information. After intensity and range background subtraction, the foreground moving objects will be detected using a density-based detector and encoded into the state-space model for tracking. The output of the proposed model includes vehicle trajectories that can enable many mobility and safety applications. The method was validated against a commercial traffic data collection platform and demonstrated to be an efficient and reliable solution for infrastructure LiDAR object detection. In contrast to the previous methods that process directly on the scattered and discrete point clouds, the proposed method can establish the less sophisticated linear relationship of the 3D measurement data, which captures the spatial-temporal structure that we often desire.