 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinal Vessels Segmentation Based on Dilated Multi-Scale Convolutional Neural Network
Paper and Code
Apr 11, 2019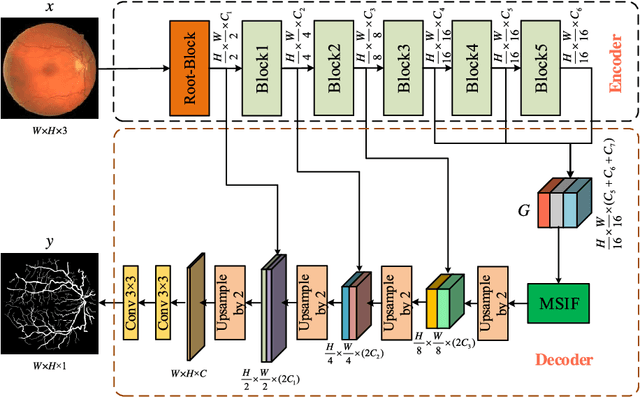

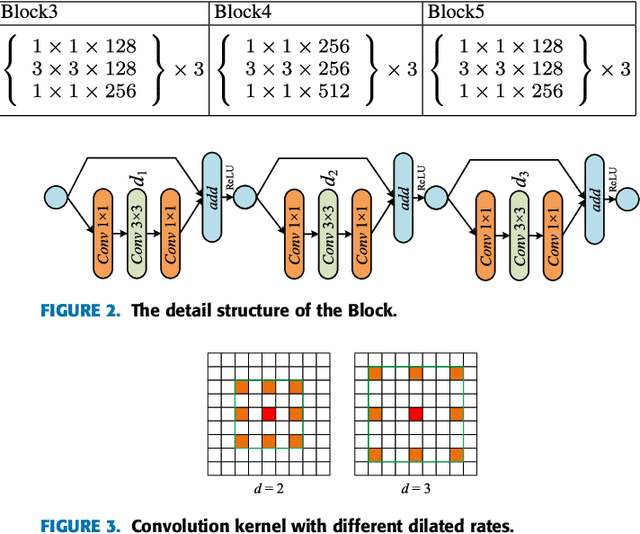
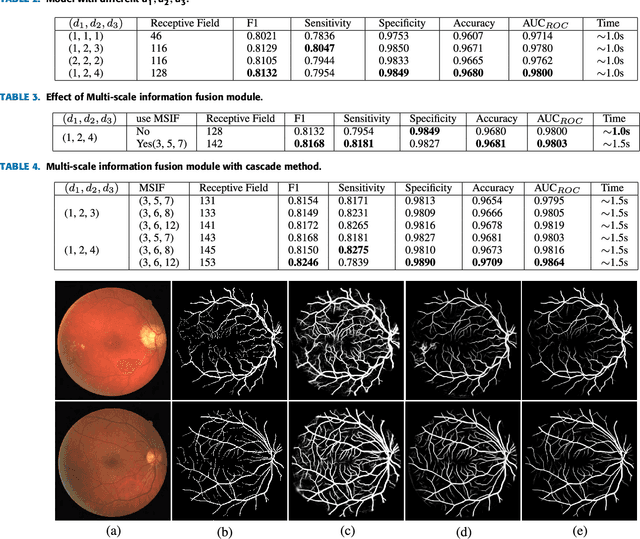
Accurate segmentation of retinal vessels is a basic step in Diabetic retinopathy(DR) detection. Most methods based on deep convolutional neural network (DCNN) have small receptive fields, and hence they are unable to capture global context information of larger regions, with difficult to identify lesions. The final segmented retina vessels contain more noise with low classification accuracy. Therefore, in this paper, we propose a DCNN structure named as D-Net. In the proposed D-Net, the dilation convolution is used in the backbone network to obtain a larger receptive field without losing spatial resolution, so as to reduce the loss of feature information and to reduce the difficulty of tiny thin vessels segmentation. The large receptive field can better distinguished between the lesion area and the blood vessel area. In the proposed Multi-Scale Information Fusion module (MSIF), parallel convolution layers with different dilation rates are used, so that the model can obtain more dense feature information and better capture retinal vessel information of different sizes. In the decoding module, the skip layer connection is used to propagate context information to higher resolution layers, so as to prevent low-level information from passing the entire network structure. Finally, our method was verified on DRIVE, STARE and CHASE dataset. The experimental results show that our network structure outperforms some state-of-art method, such as N4-fields, U-Net, and DRIU in terms of accuracy, sensitivity, specificity, and AUCROC. Particularly, D-Net outperforms U-Net by 1.04%, 1.23% and 2.79% in DRIVE, STARE, and CHASE three dataset, respectively.