 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model Can Be a Foundation for Hidden Rationale-Based Retrieval
Dec 21, 2024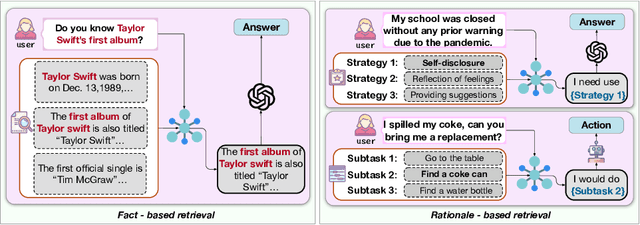
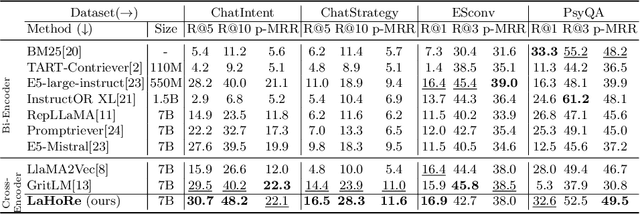
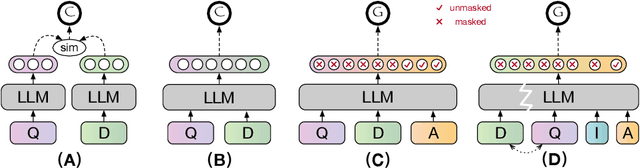
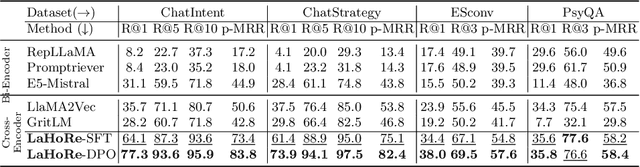
Despite the recent advancement in Retrieval-Augmented Generation (RAG) systems, most retrieval methodologies are often developed for factual retrieval, which assumes query and positive documents are semantically similar. In this paper, we instead propose and study a more challenging type of retrieval task, called hidden rationale retrieval, in which query and document are not similar but can be inferred by reasoning chains, logic relationships, or empirical experiences. To address such problems, an instruction-tuned Large language model (LLM) with a cross-encoder architecture could be a reasonable choice. To further strengthen pioneering LLM-based retrievers, we design a special instruction that transforms the retrieval task into a generative task by prompting LLM to answer a binary-choice question. The model can be fine-tuned with direct preference optimization (DPO). The framework is also optimized for computational efficiency with no performance degradation. We name this retrieval framework by RaHoRe and verify its zero-shot and fine-tuned performance superiority on Emotional Support Conversation (ESC), compared with previous retrieval works. Our study suggests the potential to employ LLM as a foundation for a wider scope of retrieval tasks. Our codes, models, and datasets are available on https://github.com/flyfree5/LaHoRe.
Alleviating Hallucinations in Large Language Models with Scepticism Modeling
Sep 10, 2024



Hallucinations is a major challenge for large language models (LLMs), prevents adoption in diverse fields. Uncertainty estimation could be used for alleviating the damages of hallucinations. The skeptical emotion of human could be useful for enhancing the ability of self estimation. Inspirited by this observation, we proposed a new approach called Skepticism Modeling (SM). This approach is formalized by combining the information of token and logits for self estimation. We construct the doubt emotion aware data, perform continual pre-training, and then fine-tune the LLMs, improve their ability of self estimation. Experimental results demonstrate this new approach effectively enhances a model's ability to estimate their uncertainty, and validate its generalization ability of other tasks by out-of-domain experiments.
Alt-MoE: Multimodal Alignment via Alternating Optimization of Multi-directional MoE with Unimodal Models
Sep 09, 2024



Recent Large Multi-Modal Models (LMMs) have made significant advancements in multi-modal alignment by employing lightweight connection modules to facilitate the representation and fusion of knowledge from existing pre-trained uni-modal models. However, these methods still rely on modality-specific and direction-specific connectors, leading to compartmentalized knowledge representations and reduced computational efficiency, which limits the model's ability to form unified multi-modal representations. To address these issues, we introduce a novel training framework, Alt-MoE, which employs the Mixture of Experts (MoE) as a unified multi-directional connector across modalities, and employs a multi-step sequential alternating unidirectional alignment strategy, which converges to bidirectional alignment over iterations. The extensive empirical studies revealed the following key points: 1) Alt-MoE achieves competitive results by integrating diverse knowledge representations from uni-modal models. This approach seamlessly fuses the specialized expertise of existing high-performance uni-modal models, effectively synthesizing their domain-specific knowledge into a cohesive multi-modal representation. 2) Alt-MoE efficiently scales to new tasks and modalities without altering its model architecture or training strategy. Furthermore, Alt-MoE operates in latent space, supporting vector pre-storage and real-time retrieval via lightweight multi-directional MoE, thereby facilitating massive data processing. Our methodology has been validated on several well-performing uni-modal models (LLAMA3, Qwen2, and DINOv2), achieving competitive results on a wide range of downstream tasks and datasets.