 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeteroCache: A Dynamic Retrieval Approach to Heterogeneous KV Cache Compression for Long-Context LLM Inference
Jan 20, 2026The linear memory growth of the KV cache poses a significant bottleneck for LLM inference in long-context tasks. Existing static compression methods often fail to preserve globally important information, principally because they overlook the attention drift phenomenon where token significance evolves dynamically. Although recent dynamic retrieval approaches attempt to address this issue, they typically suffer from coarse-grained caching strategies and incur high I/O overhead due to frequent data transfers. To overcome these limitations, we propose HeteroCache, a training-free dynamic compression framework. Our method is built on two key insights: attention heads exhibit diverse temporal heterogeneity, and there is significant spatial redundancy among heads within the same layer. Guided by these insights, HeteroCache categorizes heads based on stability and redundancy. Consequently, we apply a fine-grained weighting strategy that allocates larger cache budgets to heads with rapidly shifting attention to capture context changes, thereby addressing the inefficiency of coarse-grained strategies. Furthermore, we employ a hierarchical storage mechanism in which a subset of representative heads monitors attention shift, and trigger an asynchronous, on-demand retrieval of contexts from the CPU, effectively hiding I/O latency. Finally, experiments demonstrate that HeteroCache achieves state-of-the-art performance on multiple long-context benchmarks and accelerates decoding by up to $3\times$ compared to the original model in the 224K context. Our code will be open-source.
HEAPr: Hessian-based Efficient Atomic Expert Pruning in Output Space
Sep 26, 2025Mixture-of-Experts (MoE) architectures in large language models (LLMs) deliver exceptional performance and reduced inference costs compared to dense LLMs. However, their large parameter counts result in prohibitive memory requirements, limiting practical deployment. While existing pruning methods primarily focus on expert-level pruning, this coarse granularity often leads to substantial accuracy degradation. In this work, we introduce HEAPr, a novel pruning algorithm that decomposes experts into smaller, indivisible atomic experts, enabling more precise and flexible atomic expert pruning. To measure the importance of each atomic expert, we leverage second-order information based on principles similar to Optimal Brain Surgeon (OBS) theory. To address the computational and storage challenges posed by second-order information, HEAPr exploits the inherent properties of atomic experts to transform the second-order information from expert parameters into that of atomic expert parameters, and further simplifies it to the second-order information of atomic expert outputs. This approach reduces the space complexity from $O(d^4)$, where d is the model's dimensionality, to $O(d^2)$. HEAPr requires only two forward passes and one backward pass on a small calibration set to compute the importance of atomic experts. Extensive experiments on MoE models, including DeepSeek MoE and Qwen MoE family, demonstrate that HEAPr outperforms existing expert-level pruning methods across a wide range of compression ratios and benchmarks. Specifically, HEAPr achieves nearly lossless compression at compression ratios of 20% ~ 25% in most models, while also reducing FLOPs nearly by 20%. The code can be found at \href{https://github.com/LLIKKE/HEAPr}{https://github.com/LLIKKE/HEAPr}.
Dream to Chat: Model-based Reinforcement Learning on Dialogues with User Belief Modeling
Aug 23, 2025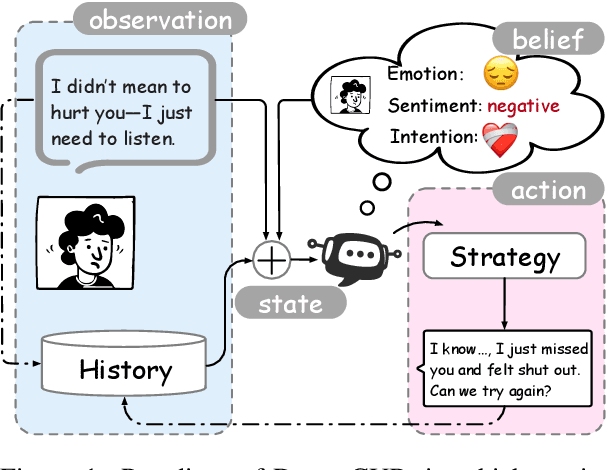
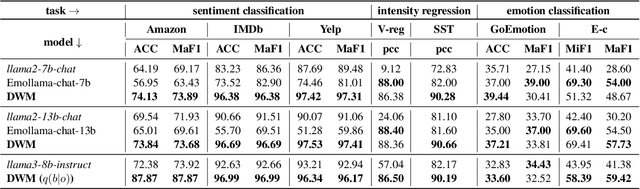
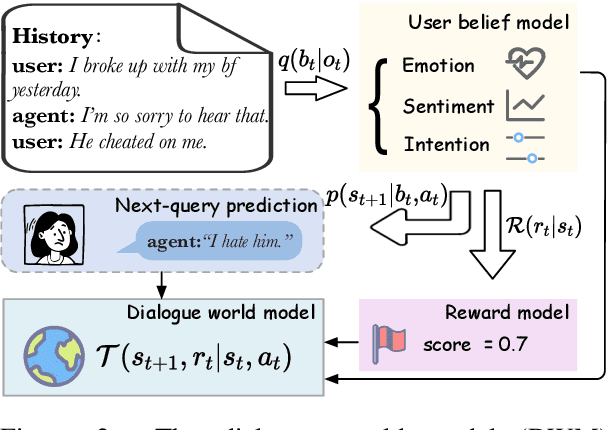
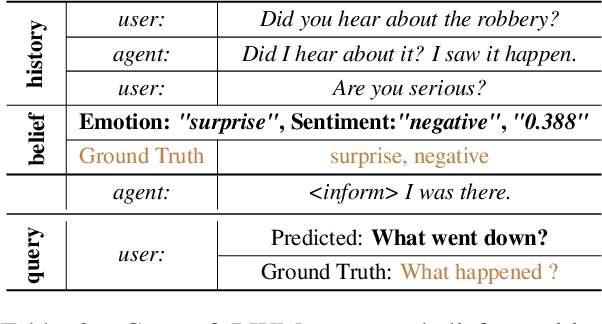
World models have been widely utilized in robotics, gaming, and auto-driving. However, their applications on natural language tasks are relatively limited. In this paper, we construct the dialogue world model, which could predict the user's emotion, sentiment, and intention, and future utterances. By defining a POMDP, we argue emotion, sentiment and intention can be modeled as the user belief and solved by maximizing the information bottleneck. By this user belief modeling, we apply the model-based reinforcement learning framework to the dialogue system, and propose a framework called DreamCUB. Experiments show that the pretrained dialogue world model can achieve state-of-the-art performances on emotion classification and sentiment identification, while dialogue quality is also enhanced by joint training of the policy, critic and dialogue world model. Further analysis shows that this manner holds a reasonable exploration-exploitation balance and also transfers well to out-of-domain scenarios such as empathetic dialogues.
Convert Language Model into a Value-based Strategic Planner
May 11, 2025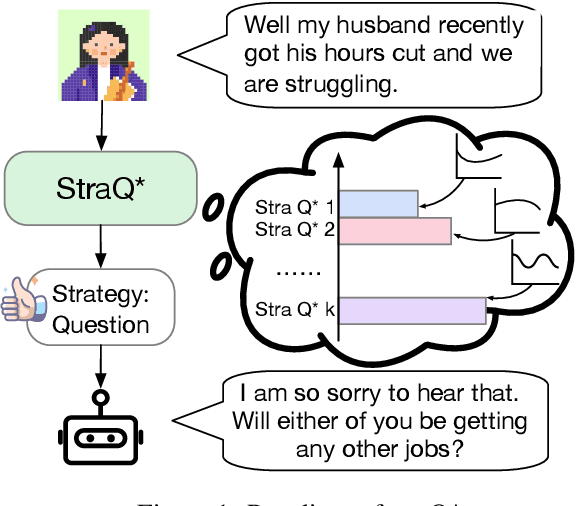
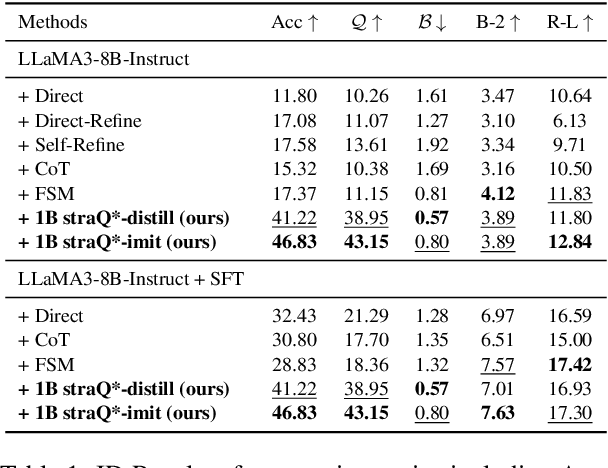
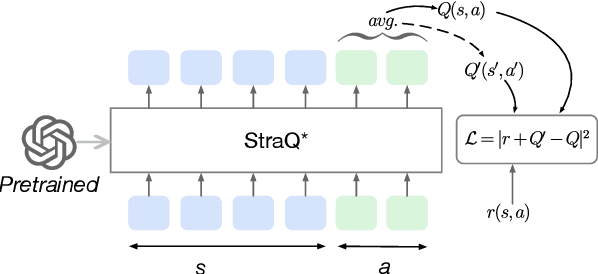
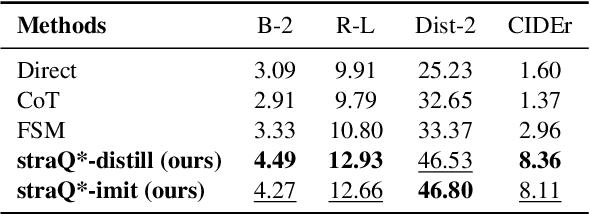
Emotional support conversation (ESC) aims to alleviate the emotional distress of individuals through effective conversations. Although large language models (LLMs) have obtained remarkable progress on ESC, most of these studies might not define the diagram from the state model perspective, therefore providing a suboptimal solution for long-term satisfaction. To address such an issue, we leverage the Q-learning on LLMs, and propose a framework called straQ*. Our framework allows a plug-and-play LLM to bootstrap the planning during ESC, determine the optimal strategy based on long-term returns, and finally guide the LLM to response. Substantial experiments on ESC datasets suggest that straQ* outperforms many baselines, including direct inference, self-refine, chain of thought, finetuning, and finite state machines.
FiSMiness: A Finite State Machine Based Paradigm for Emotional Support Conversations
Apr 16, 2025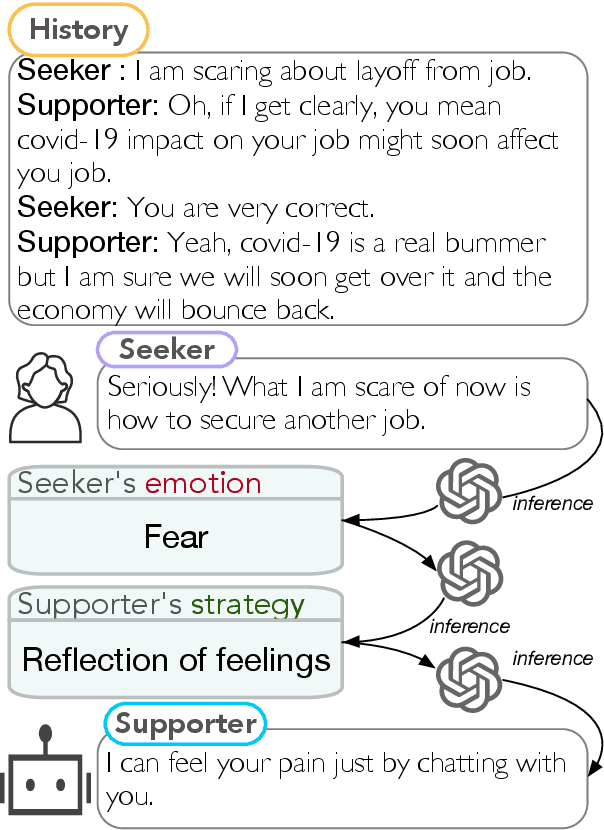
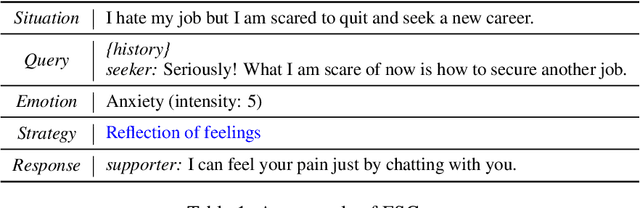
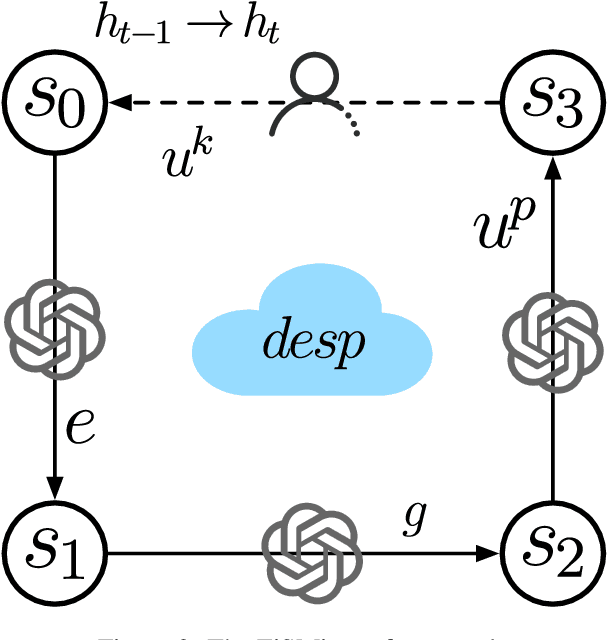
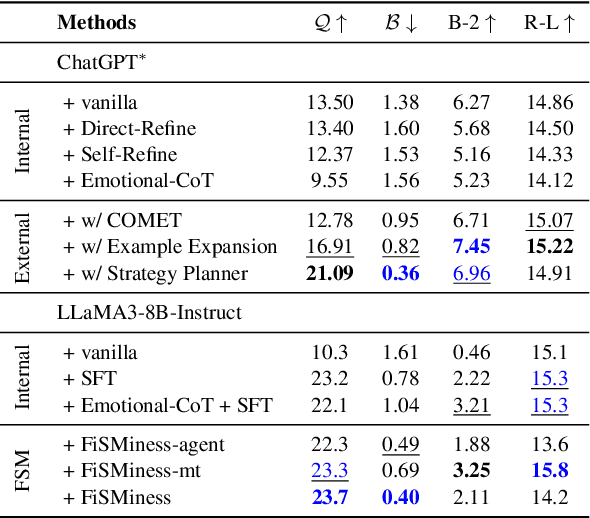
Emotional support conversation (ESC) aims to alleviate the emotional distress of individuals through effective conversations. Although large language models (LLMs) have obtained remarkable progress on ESC, most of these studies might not define the diagram from the state model perspective, therefore providing a suboptimal solution for long-term satisfaction. To address such an issue, we leverage the Finite State Machine (FSM) on LLMs, and propose a framework called FiSMiness. Our framework allows a single LLM to bootstrap the planning during ESC, and self-reason the seeker's emotion, support strategy and the final response upon each conversational turn. Substantial experiments on ESC datasets suggest that FiSMiness outperforms many baselines, including direct inference, self-refine, chain of thought, finetuning, and external-assisted methods, even those with many more parameters.
Generative Reliability-Based Design Optimization Using In-Context Learning Capabilities of Large Language Models
Mar 28, 2025Large Language Models (LLMs) have demonstrated remarkable in-context learning capabilities, enabling flexible utilization of limited historical information to play pivotal roles in reasoning, problem-solving, and complex pattern recognition tasks. Inspired by the successful applications of LLMs in multiple domains, this paper proposes a generative design method by leveraging the in-context learning capabilities of LLMs with the iterative search mechanisms of metaheuristic algorithms for solving reliability-based design optimization problems. In detail, reliability analysis is performed by engaging the LLMs and Kriging surrogate modeling to overcome the computational burden. By dynamically providing critical information of design points to the LLMs with prompt engineering, the method enables rapid generation of high-quality design alternatives that satisfy reliability constraints while achieving performance optimization. With the Deepseek-V3 model, three case studies are used to demonstrated the performance of the proposed approach. Experimental results indicate that the proposed LLM-RBDO method successfully identifies feasible solutions that meet reliability constraints while achieving a comparable convergence rate compared to traditional genetic algorithms.
Large Language Model Can Be a Foundation for Hidden Rationale-Based Retrieval
Dec 21, 2024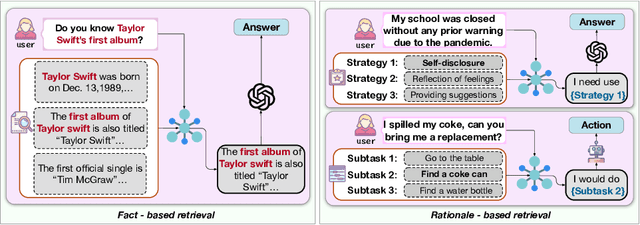
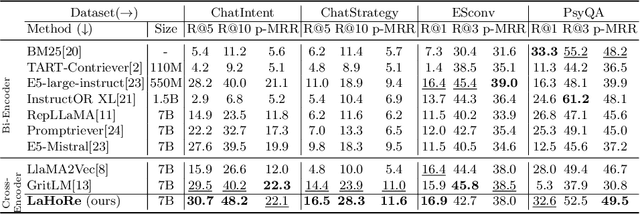
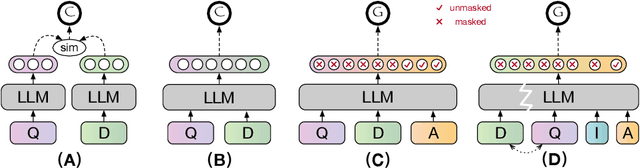
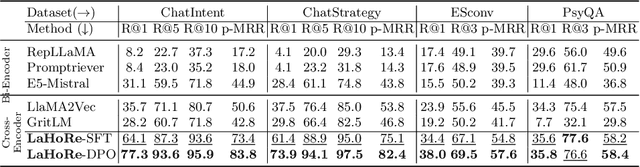
Despite the recent advancement in Retrieval-Augmented Generation (RAG) systems, most retrieval methodologies are often developed for factual retrieval, which assumes query and positive documents are semantically similar. In this paper, we instead propose and study a more challenging type of retrieval task, called hidden rationale retrieval, in which query and document are not similar but can be inferred by reasoning chains, logic relationships, or empirical experiences. To address such problems, an instruction-tuned Large language model (LLM) with a cross-encoder architecture could be a reasonable choice. To further strengthen pioneering LLM-based retrievers, we design a special instruction that transforms the retrieval task into a generative task by prompting LLM to answer a binary-choice question. The model can be fine-tuned with direct preference optimization (DPO). The framework is also optimized for computational efficiency with no performance degradation. We name this retrieval framework by RaHoRe and verify its zero-shot and fine-tuned performance superiority on Emotional Support Conversation (ESC), compared with previous retrieval works. Our study suggests the potential to employ LLM as a foundation for a wider scope of retrieval tasks. Our codes, models, and datasets are available on https://github.com/flyfree5/LaHoRe.
Multi-Party Supervised Fine-tuning of Language Models for Multi-Party Dialogue Generation
Dec 06, 2024Large Language Models (LLM) are usually fine-tuned to participate in dyadic or two-party dialogues, which can not adapt well to multi-party dialogues (MPD), which hinders their applications in such scenarios including multi-personal meetings, discussions and daily communication. Previous LLM-based researches mainly focus on the multi-agent framework, while their base LLMs are still pairwisely fine-tuned. In this work, we design a multi-party fine-tuning framework (MuPaS) for LLMs on the multi-party dialogue datasets, and prove such a straightforward framework can let the LLM align with the multi-party conversation style efficiently and effectively. We also design two training strategies which can convert MuPaS into the MPD simulator. Substantial experiments show that MuPaS can achieve state-of-the-art multi-party response, higher accuracy of the-next-speaker prediction, higher human and automatic evaluated utterance qualities, and can even generate reasonably with out-of-distribution scene, topic and role descriptions. The MuPaS framework bridges the LLM training with more complicated multi-party applications, such as conversation generation, virtual rehearsal or meta-universe.
Dual-Layer Training and Decoding of Large Language Model with Simultaneously Thinking and Speaking
Sep 18, 2024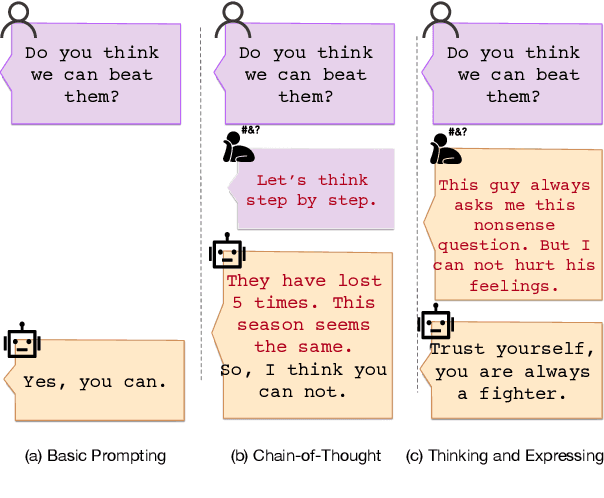



Large Language Model can reasonably understand and generate human expressions but may lack of thorough thinking and reasoning mechanisms. Recently there have been several studies which enhance the thinking ability of language models but most of them are not data-driven or training-based. In this paper, we are motivated by the cognitive mechanism in the natural world, and design a novel model architecture called TaS which allows it to first consider the thoughts and then express the response based upon the query. We design several pipelines to annotate or generate the thought contents from prompt-response samples, then add language heads in a middle layer which behaves as the thinking layer. We train the language model by the thoughts-augmented data and successfully let the thinking layer automatically generate reasonable thoughts and finally output more reasonable responses. Both qualitative examples and quantitative results validate the effectiveness and performance of TaS. Our code is available at https://anonymous.4open.science/r/TadE.
Alleviating Hallucinations in Large Language Models with Scepticism Modeling
Sep 10, 2024



Hallucinations is a major challenge for large language models (LLMs), prevents adoption in diverse fields. Uncertainty estimation could be used for alleviating the damages of hallucinations. The skeptical emotion of human could be useful for enhancing the ability of self estimation. Inspirited by this observation, we proposed a new approach called Skepticism Modeling (SM). This approach is formalized by combining the information of token and logits for self estimation. We construct the doubt emotion aware data, perform continual pre-training, and then fine-tune the LLMs, improve their ability of self estimation. Experimental results demonstrate this new approach effectively enhances a model's ability to estimate their uncertainty, and validate its generalization ability of other tasks by out-of-domain experiments.