 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Reliability-Based Design Optimization Using In-Context Learning Capabilities of Large Language Models
Mar 28, 2025Large Language Models (LLMs) have demonstrated remarkable in-context learning capabilities, enabling flexible utilization of limited historical information to play pivotal roles in reasoning, problem-solving, and complex pattern recognition tasks. Inspired by the successful applications of LLMs in multiple domains, this paper proposes a generative design method by leveraging the in-context learning capabilities of LLMs with the iterative search mechanisms of metaheuristic algorithms for solving reliability-based design optimization problems. In detail, reliability analysis is performed by engaging the LLMs and Kriging surrogate modeling to overcome the computational burden. By dynamically providing critical information of design points to the LLMs with prompt engineering, the method enables rapid generation of high-quality design alternatives that satisfy reliability constraints while achieving performance optimization. With the Deepseek-V3 model, three case studies are used to demonstrated the performance of the proposed approach. Experimental results indicate that the proposed LLM-RBDO method successfully identifies feasible solutions that meet reliability constraints while achieving a comparable convergence rate compared to traditional genetic algorithms.
Semi-supervised deep learning for high-dimensional uncertainty quantification
Jun 01, 2020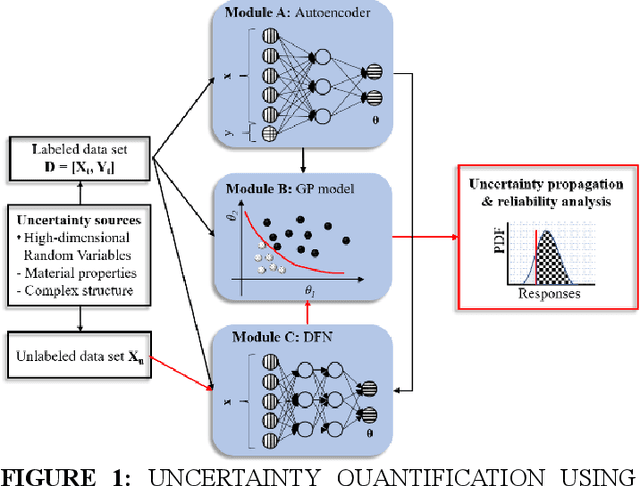
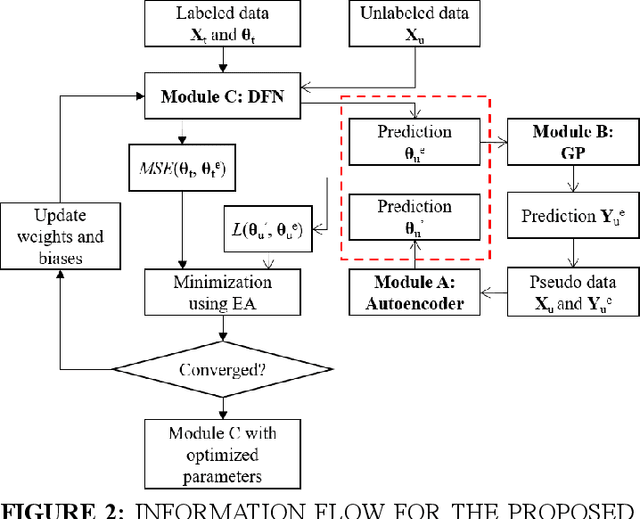
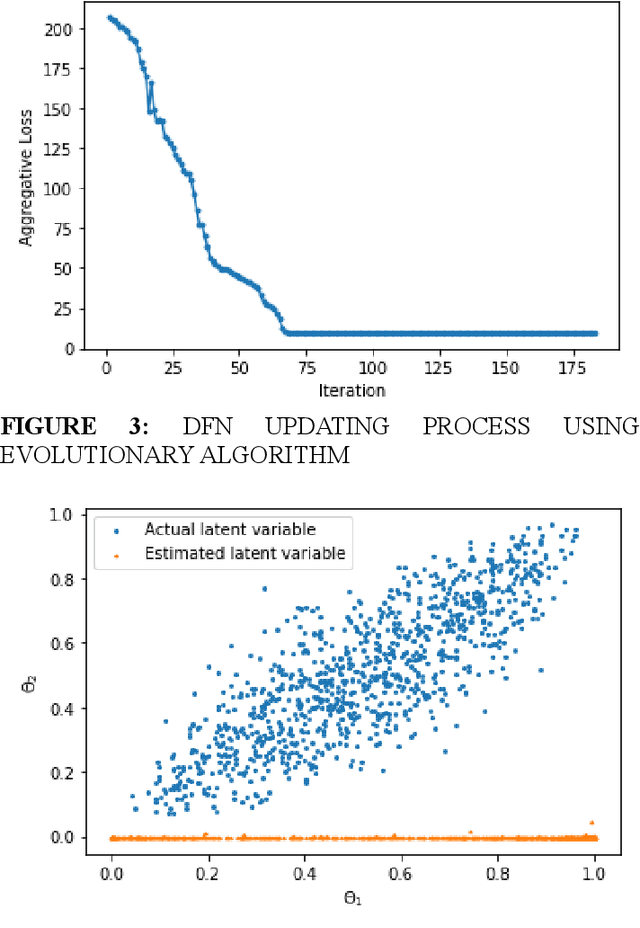
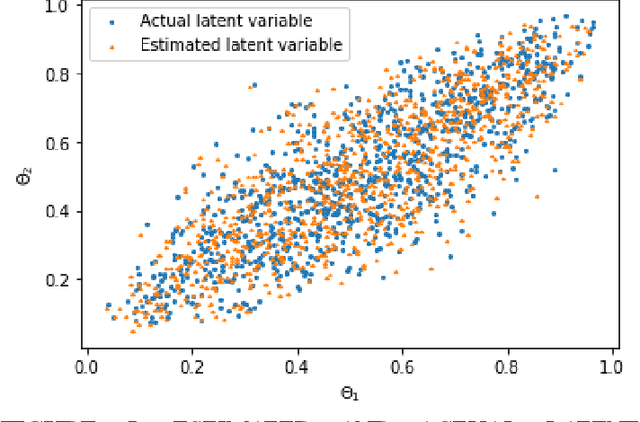
Conventional uncertainty quantification methods usually lacks the capability of dealing with high-dimensional problems due to the curse of dimensionality. This paper presents a semi-supervised learning framework for dimension reduction and reliability analysis. An autoencoder is first adopted for mapping the high-dimensional space into a low-dimensional latent space, which contains a distinguishable failure surface. Then a deep feedforward neural network (DFN) is utilized to learn the mapping relationship and reconstruct the latent space, while the Gaussian process (GP) modeling technique is used to build the surrogate model of the transformed limit state function. During the training process of the DFN, the discrepancy between the actual and reconstructed latent space is minimized through semi-supervised learning for ensuring the accuracy. Both labeled and unlabeled samples are utilized for defining the loss function of the DFN. Evolutionary algorithm is adopted to train the DFN, then the Monte Carlo simulation method is used for uncertainty quantification and reliability analysis based on the proposed framework. The effectiveness is demonstrated through a mathematical example.
Proximal Reliability Optimization for Reinforcement Learning
Jun 03, 2019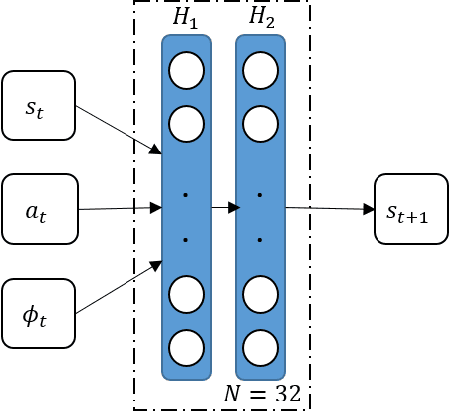
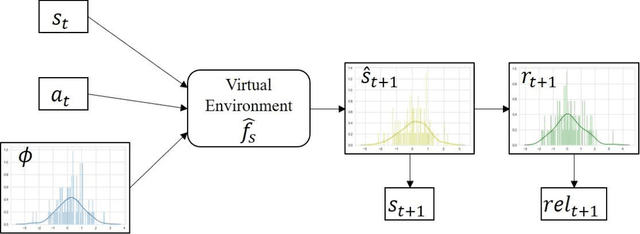
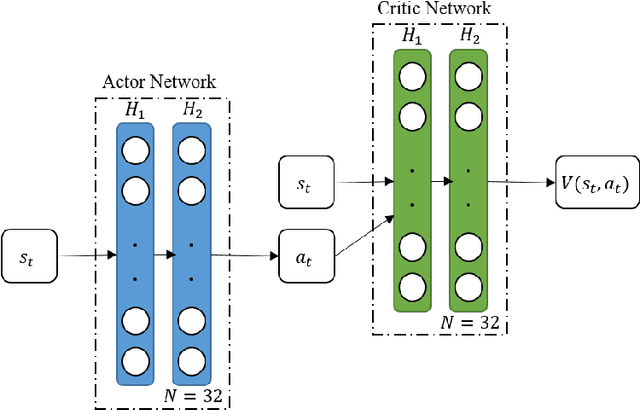
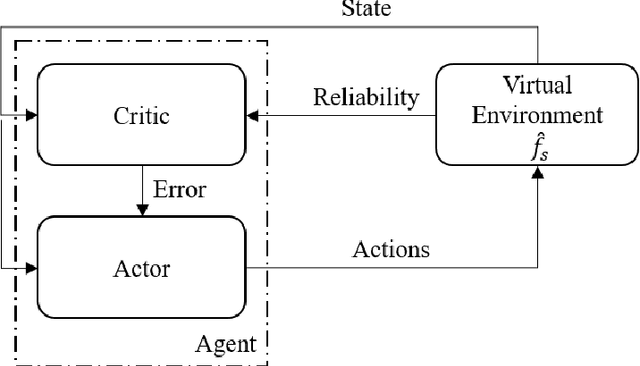
Despite the numerous advances, reinforcement learning remains away from widespread acceptance for autonomous controller design as compared to classical methods due to lack of ability to effectively tackle the reality gap. The reliance on absolute or deterministic reward as a metric for optimization process renders reinforcement learning highly susceptible to changes in problem dynamics. We introduce a novel framework that effectively quantizes the uncertainty of the design space and induces robustness in controllers by switching to a reliability-based optimization routine. The data efficiency of the method is maintained to match reward based optimization methods by employing a model-based approach. We prove the stability of learned neuro-controllers in both static and dynamic environments on classical reinforcement learning tasks such as Cart Pole balancing and Inverted Pendulum.
Reinforcement Learning for Robotics and Control with Active Uncertainty Reduction
May 15, 2019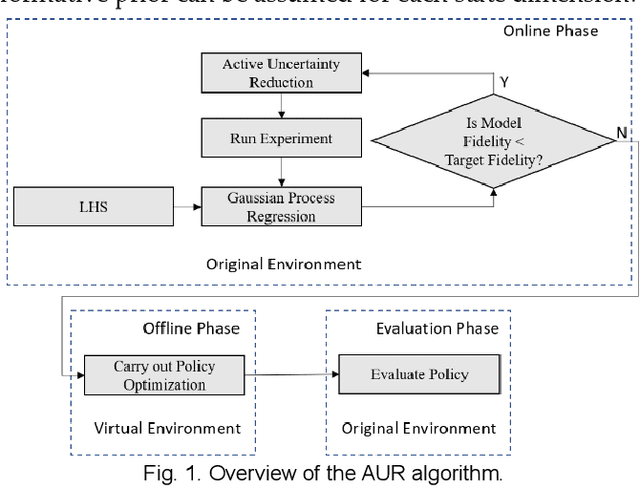
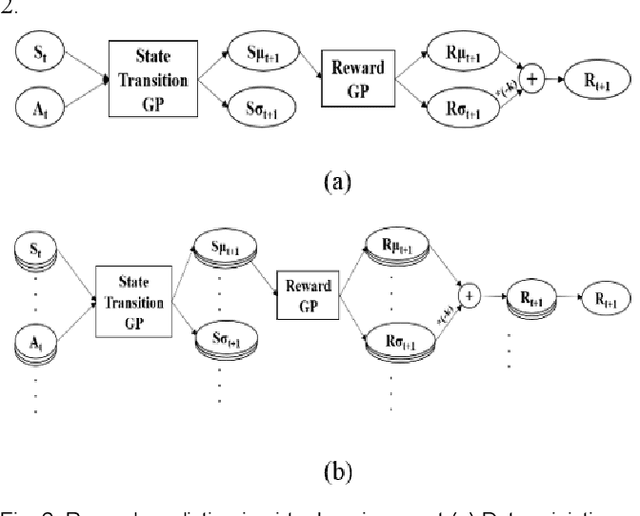
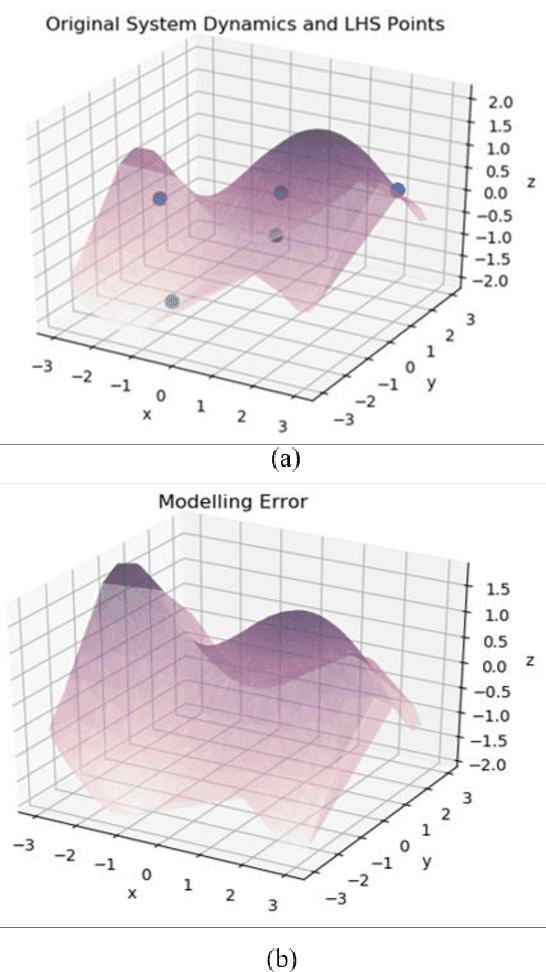
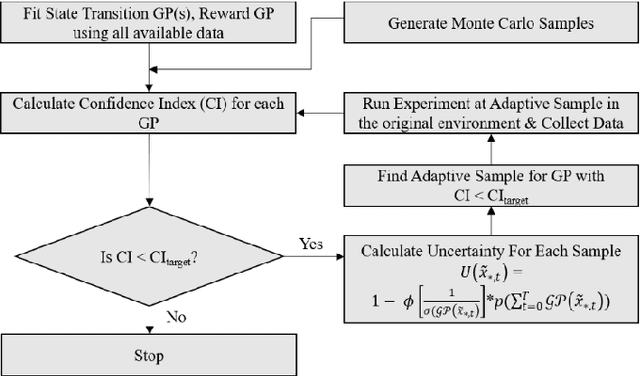
Model-free reinforcement learning based methods such as Proximal Policy Optimization, or Q-learning typically require thousands of interactions with the environment to approximate the optimum controller which may not always be feasible in robotics due to safety and time consumption. Model-based methods such as PILCO or BlackDrops, while data-efficient, provide solutions with limited robustness and complexity. To address this tradeoff, we introduce active uncertainty reduction-based virtual environments, which are formed through limited trials conducted in the original environment. We provide an efficient method for uncertainty management, which is used as a metric for self-improvement by identification of the points with maximum expected improvement through adaptive sampling. Capturing the uncertainty also allows for better mimicking of the reward responses of the original system. Our approach enables the use of complex policy structures and reward functions through a unique combination of model-based and model-free methods, while still retaining the data efficiency. We demonstrate the validity of our method on several classic reinforcement learning problems in OpenAI gym. We prove that our approach offers a better modeling capacity for complex system dynamics as compared to established methods.