 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Robotics and Control with Active Uncertainty Reduction
Paper and Code
May 15, 2019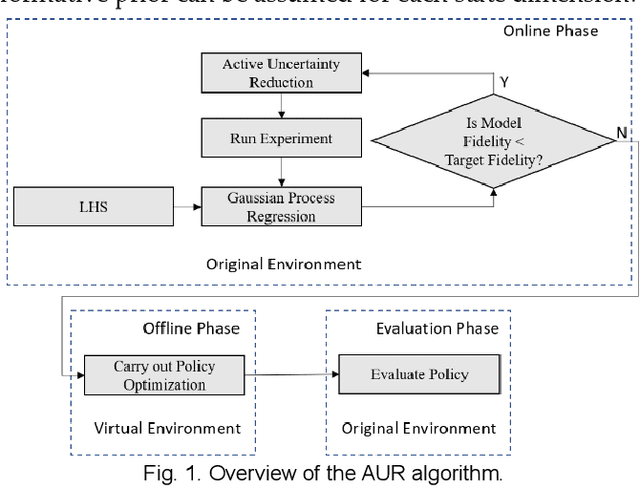
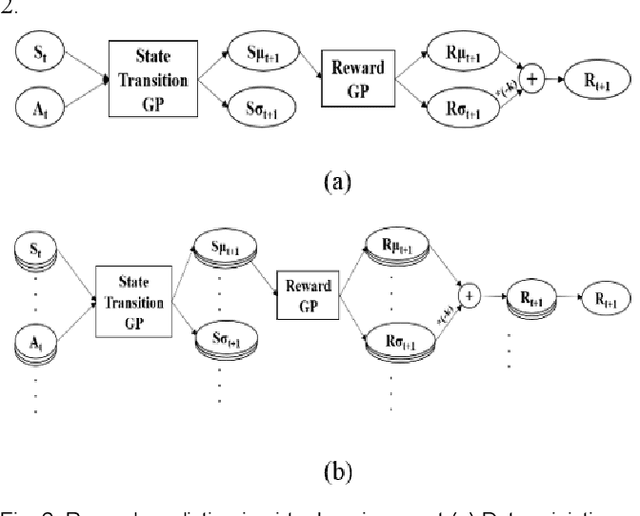
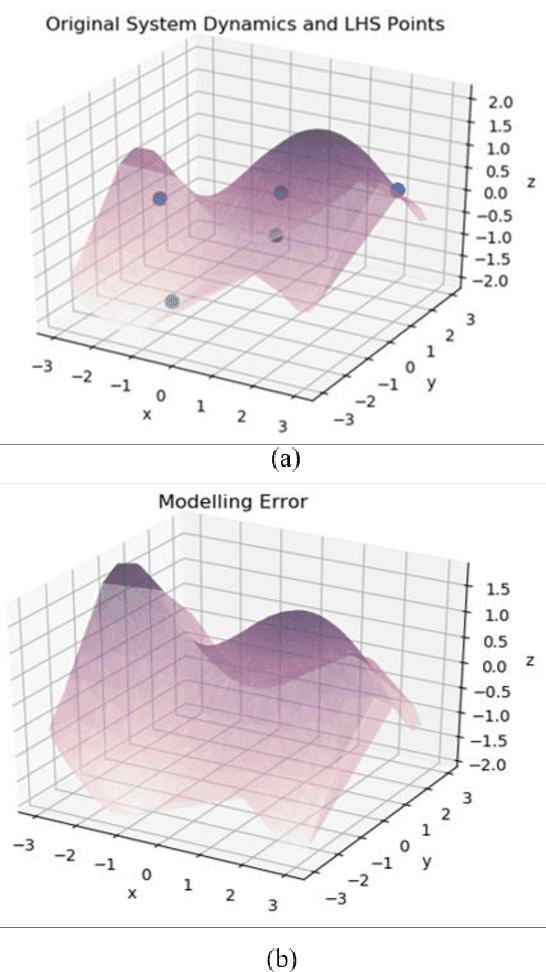
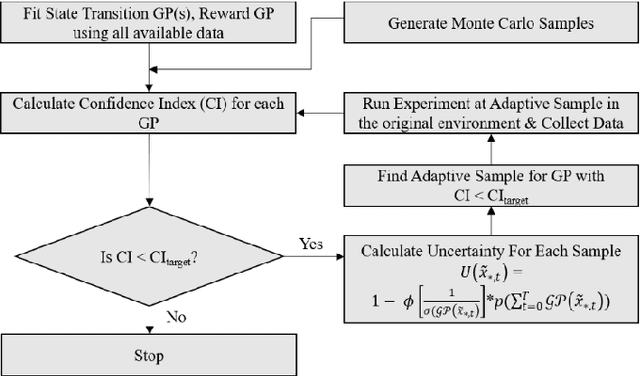
Model-free reinforcement learning based methods such as Proximal Policy Optimization, or Q-learning typically require thousands of interactions with the environment to approximate the optimum controller which may not always be feasible in robotics due to safety and time consumption. Model-based methods such as PILCO or BlackDrops, while data-efficient, provide solutions with limited robustness and complexity. To address this tradeoff, we introduce active uncertainty reduction-based virtual environments, which are formed through limited trials conducted in the original environment. We provide an efficient method for uncertainty management, which is used as a metric for self-improvement by identification of the points with maximum expected improvement through adaptive sampling. Capturing the uncertainty also allows for better mimicking of the reward responses of the original system. Our approach enables the use of complex policy structures and reward functions through a unique combination of model-based and model-free methods, while still retaining the data efficiency. We demonstrate the validity of our method on several classic reinforcement learning problems in OpenAI gym. We prove that our approach offers a better modeling capacity for complex system dynamics as compared to established methods.