 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigitization of Raster Logs: A Deep Learning Approach
Oct 11, 2022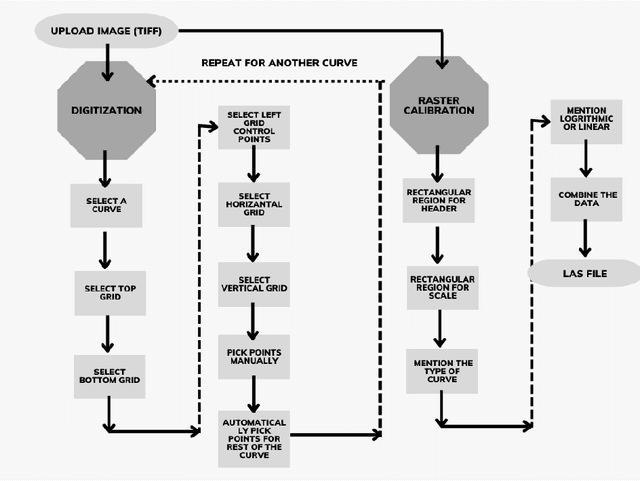
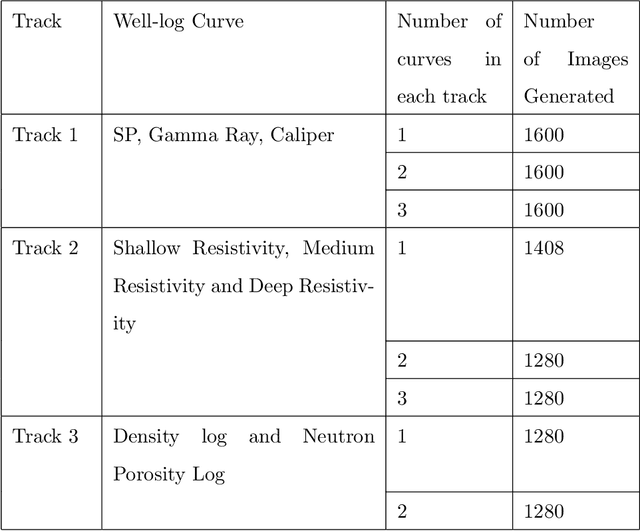
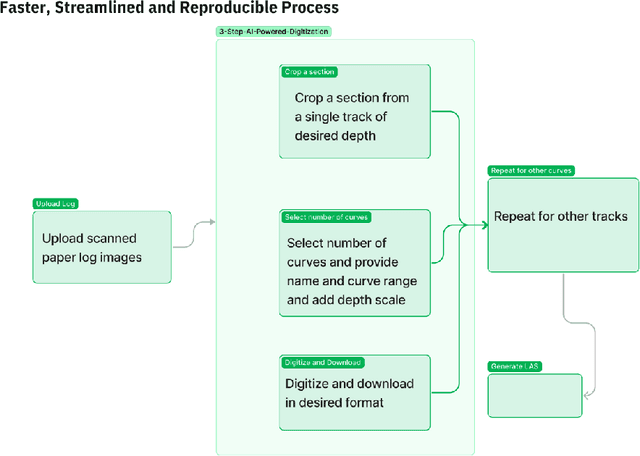

Raster well-log images are digital representations of well-logs data generated over the years. Raster digital well logs represent bitmaps of the log image in a rectangular array of black (zeros) and white dots (ones) called pixels. Experts study the raster logs manually or with software applications that still require a tremendous amount of manual input. Besides the loss of thousands of person-hours, this process is erroneous and tedious. To digitize these raster logs, one must buy a costly digitizer that is not only manual and time-consuming but also a hidden technical debt since enterprises stand to lose more money in additional servicing and consulting charges. We propose a deep neural network architecture called VeerNet to semantically segment the raster images from the background grid and classify and digitize the well-log curves. Raster logs have a substantially greater resolution than images traditionally consumed by image segmentation pipelines. Since the input has a low signal-to-resolution ratio, we require rapid downsampling to alleviate unnecessary computation. We thus employ a modified UNet-inspired architecture that balances retaining key signals and reducing result dimensionality. We use attention augmented read-process-write architecture. This architecture efficiently classifies and digitizes the curves with an overall F1 score of 35% and IoU of 30%. When compared to the actual las values for Gamma-ray and derived value of Gamma-ray from VeerNet, a high Pearson coefficient score of 0.62 was achieved.
Proximal Reliability Optimization for Reinforcement Learning
Jun 03, 2019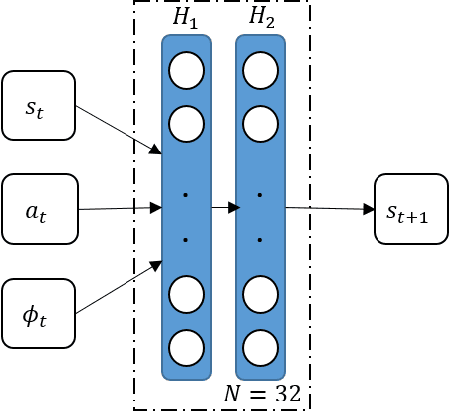
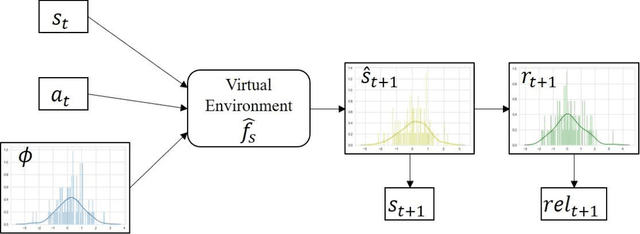
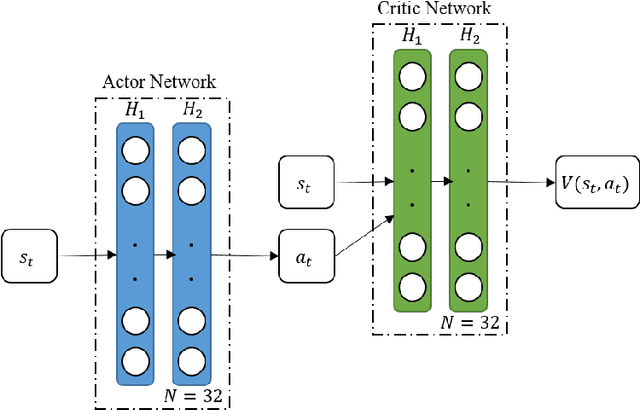
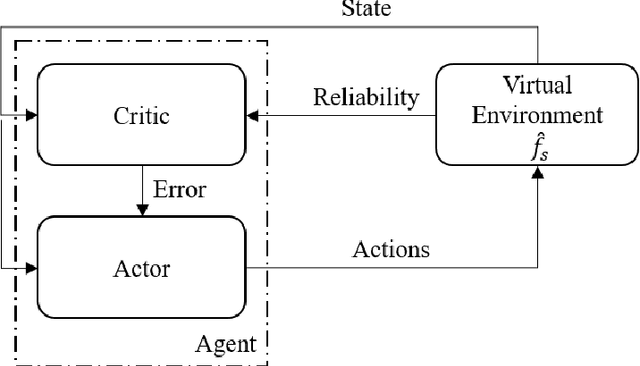
Despite the numerous advances, reinforcement learning remains away from widespread acceptance for autonomous controller design as compared to classical methods due to lack of ability to effectively tackle the reality gap. The reliance on absolute or deterministic reward as a metric for optimization process renders reinforcement learning highly susceptible to changes in problem dynamics. We introduce a novel framework that effectively quantizes the uncertainty of the design space and induces robustness in controllers by switching to a reliability-based optimization routine. The data efficiency of the method is maintained to match reward based optimization methods by employing a model-based approach. We prove the stability of learned neuro-controllers in both static and dynamic environments on classical reinforcement learning tasks such as Cart Pole balancing and Inverted Pendulum.
Reinforcement Learning for Robotics and Control with Active Uncertainty Reduction
May 15, 2019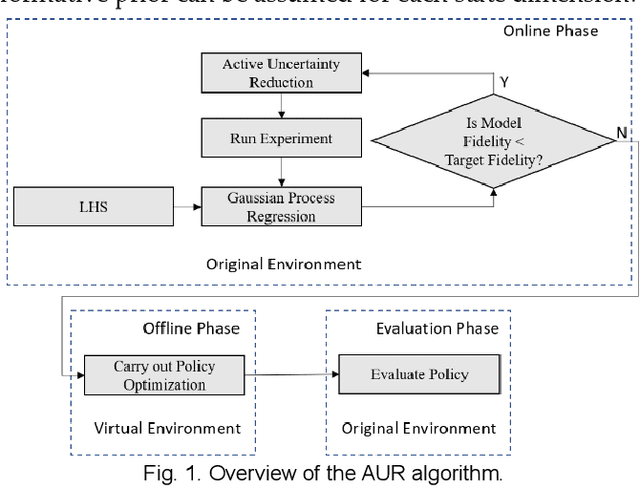
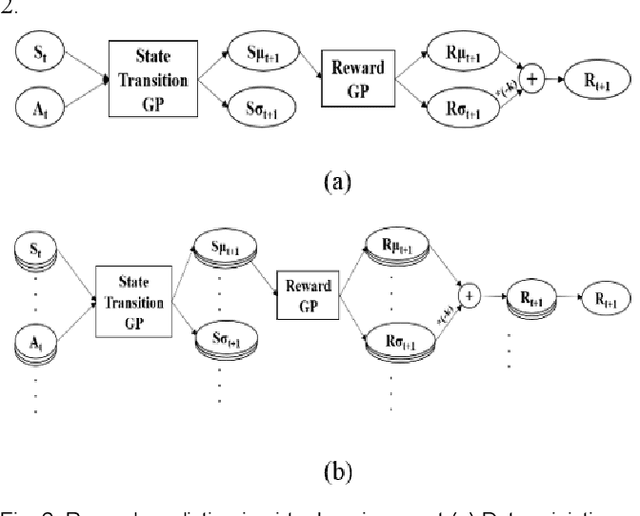
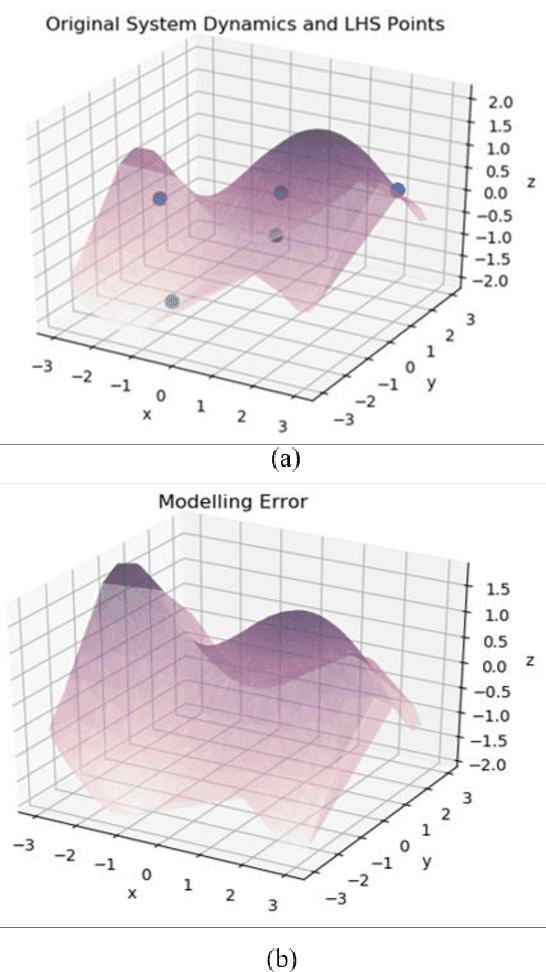
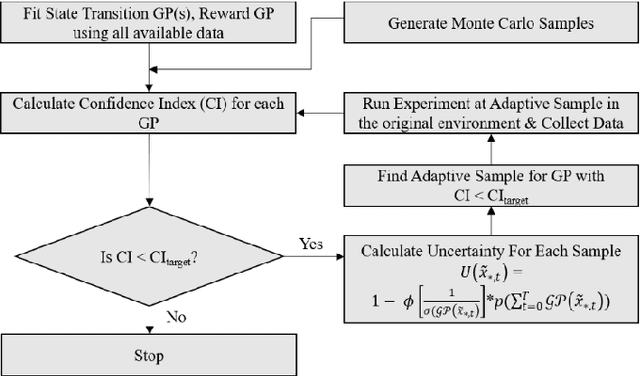
Model-free reinforcement learning based methods such as Proximal Policy Optimization, or Q-learning typically require thousands of interactions with the environment to approximate the optimum controller which may not always be feasible in robotics due to safety and time consumption. Model-based methods such as PILCO or BlackDrops, while data-efficient, provide solutions with limited robustness and complexity. To address this tradeoff, we introduce active uncertainty reduction-based virtual environments, which are formed through limited trials conducted in the original environment. We provide an efficient method for uncertainty management, which is used as a metric for self-improvement by identification of the points with maximum expected improvement through adaptive sampling. Capturing the uncertainty also allows for better mimicking of the reward responses of the original system. Our approach enables the use of complex policy structures and reward functions through a unique combination of model-based and model-free methods, while still retaining the data efficiency. We demonstrate the validity of our method on several classic reinforcement learning problems in OpenAI gym. We prove that our approach offers a better modeling capacity for complex system dynamics as compared to established methods.
ARiA: Utilizing Richard's Curve for Controlling the Non-monotonicity of the Activation Function in Deep Neural Nets
May 22, 2018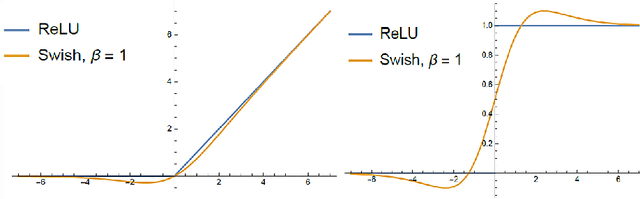
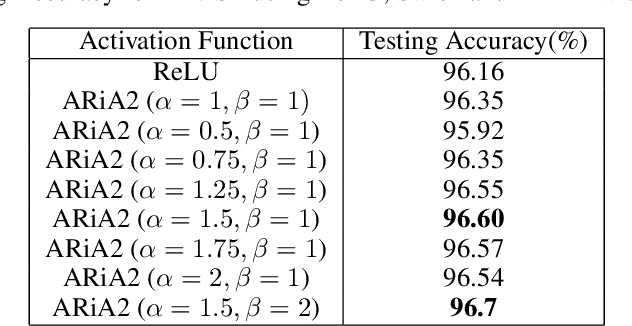
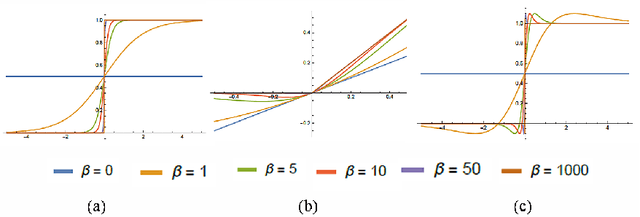

This work introduces a novel activation unit that can be efficiently employed in deep neural nets (DNNs) and performs significantly better than the traditional Rectified Linear Units (ReLU). The function developed is a two parameter version of the specialized Richard's Curve and we call it Adaptive Richard's Curve weighted Activation (ARiA). This function is non-monotonous, analogous to the newly introduced Swish, however allows a precise control over its non-monotonous convexity by varying the hyper-parameters. We first demonstrate the mathematical significance of the two parameter ARiA followed by its application to benchmark problems such as MNIST, CIFAR-10 and CIFAR-100, where we compare the performance with ReLU and Swish units. Our results illustrate a significantly superior performance on all these datasets, making ARiA a potential replacement for ReLU and other activations in DNNs.