 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProximal Reliability Optimization for Reinforcement Learning
Paper and Code
Jun 03, 2019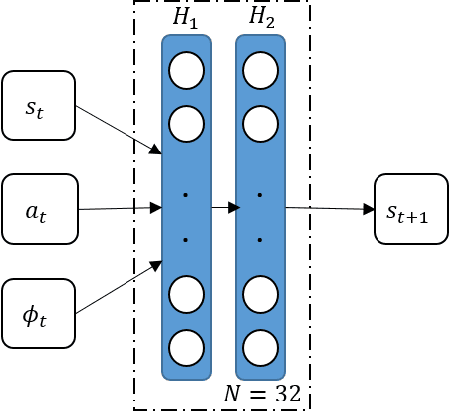
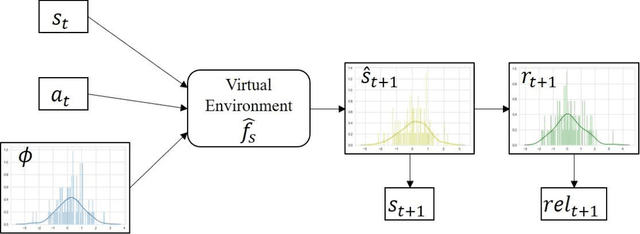
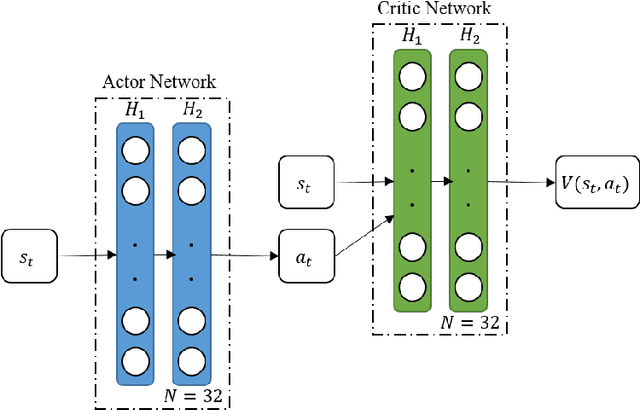
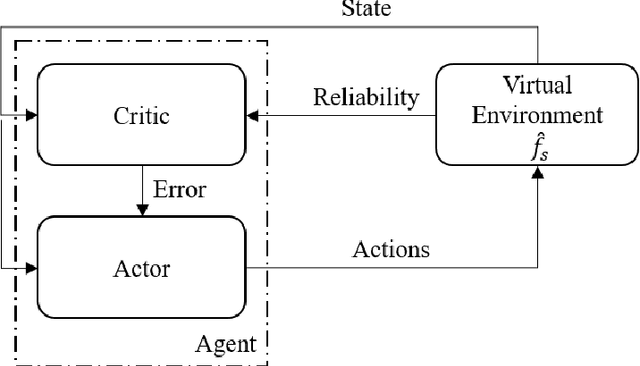
Despite the numerous advances, reinforcement learning remains away from widespread acceptance for autonomous controller design as compared to classical methods due to lack of ability to effectively tackle the reality gap. The reliance on absolute or deterministic reward as a metric for optimization process renders reinforcement learning highly susceptible to changes in problem dynamics. We introduce a novel framework that effectively quantizes the uncertainty of the design space and induces robustness in controllers by switching to a reliability-based optimization routine. The data efficiency of the method is maintained to match reward based optimization methods by employing a model-based approach. We prove the stability of learned neuro-controllers in both static and dynamic environments on classical reinforcement learning tasks such as Cart Pole balancing and Inverted Pendulum.