 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoad-aware Monocular Structure from Motion and Homography Estimation
Dec 16, 2021

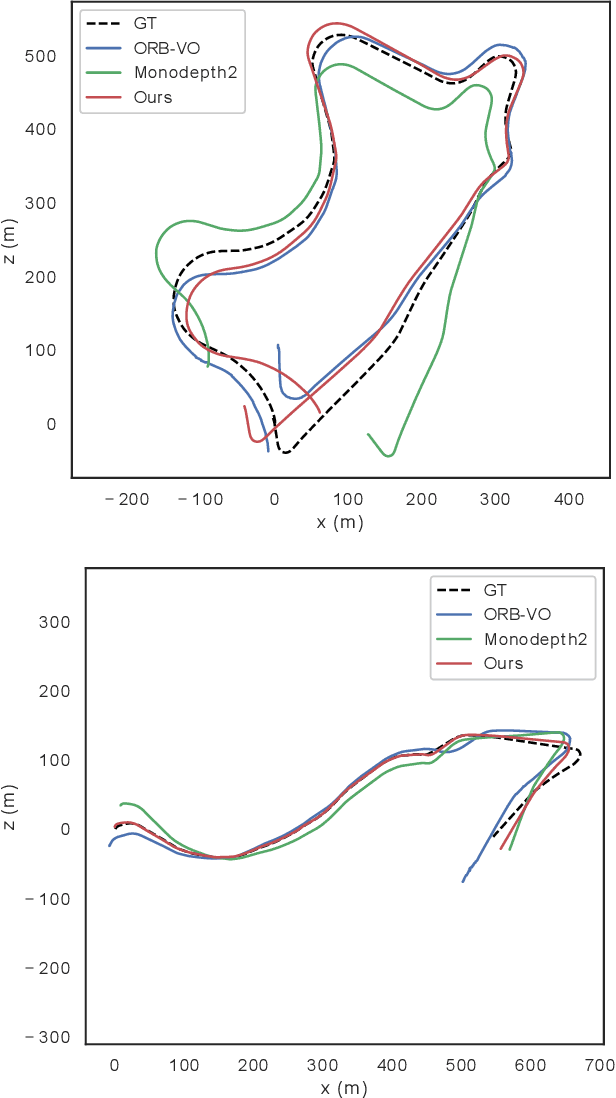

Structure from motion (SFM) and ground plane homography estimation are critical to autonomous driving and other robotics applications. Recently, much progress has been made in using deep neural networks for SFM and homography estimation respectively. However, directly applying existing methods for ground plane homography estimation may fail because the road is often a small part of the scene. Besides, the performances of deep SFM approaches are still inferior to traditional methods. In this paper, we propose a method that learns to solve both problems in an end-to-end manner, improving performance on both. The proposed networks consist of a Depth-CNN, a Pose-CNN and a Ground-CNN. The Depth-CNN and Pose-CNN estimate dense depth map and ego-motion respectively, solving SFM, while the Pose-CNN and Ground-CNN followed by a homography layer solve the ground plane estimation problem. By enforcing coherency between SFM and homography estimation results, the whole network can be trained end to end using photometric loss and homography loss without any groundtruth except the road segmentation provided by an off-the-shelf segmenter. Comprehensive experiments are conducted on KITTI benchmark to demonstrate promising results compared with various state-of-the-art approaches.