 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Multi-Lingual Vision-Language Learning in Remote Sensing Image Captioning
Paper and Code
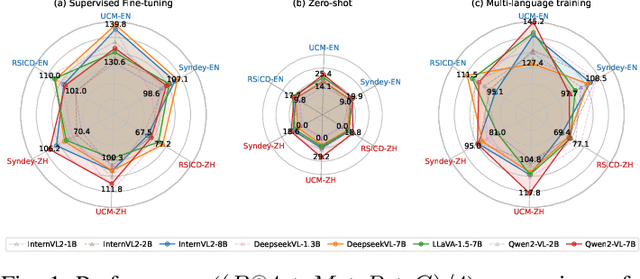

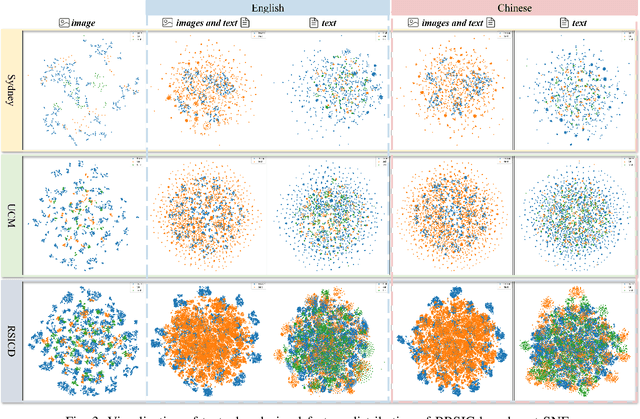
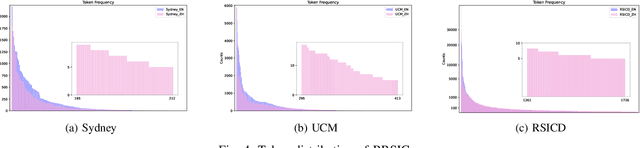
Remote Sensing Image Captioning (RSIC) is a cross-modal field bridging vision and language, aimed at automatically generating natural language descriptions of features and scenes in remote sensing imagery. Despite significant advances in developing sophisticated methods and large-scale datasets for training vision-language models (VLMs), two critical challenges persist: the scarcity of non-English descriptive datasets and the lack of multilingual capability evaluation for models. These limitations fundamentally impede the progress and practical deployment of RSIC, particularly in the era of large VLMs. To address these challenges, this paper presents several significant contributions to the field. First, we introduce and analyze BRSIC (Bilingual Remote Sensing Image Captioning), a comprehensive bilingual dataset that enriches three established English RSIC datasets with Chinese descriptions, encompassing 13,634 images paired with 68,170 bilingual captions. Building upon this foundation, we develop a systematic evaluation framework that addresses the prevalent inconsistency in evaluation protocols, enabling rigorous assessment of model performance through standardized retraining procedures on BRSIC. Furthermore, we present an extensive empirical study of eight state-of-the-art large vision-language models (LVLMs), examining their capabilities across multiple paradigms including zero-shot inference, supervised fine-tuning, and multi-lingual training. This comprehensive evaluation provides crucial insights into the strengths and limitations of current LVLMs in handling multilingual remote sensing tasks. Additionally, our cross-dataset transfer experiments reveal interesting findings. The code and data will be available at https://github.com/mrazhou/BRSIC.