 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear-Time WordPiece Tokenization
Paper and Code

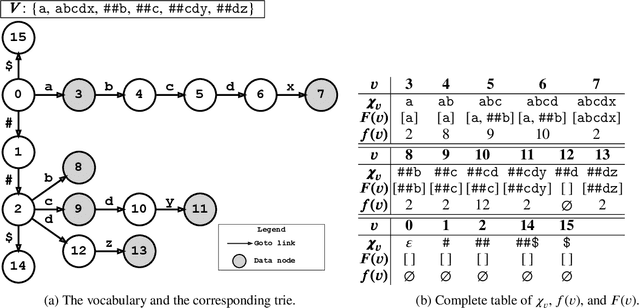

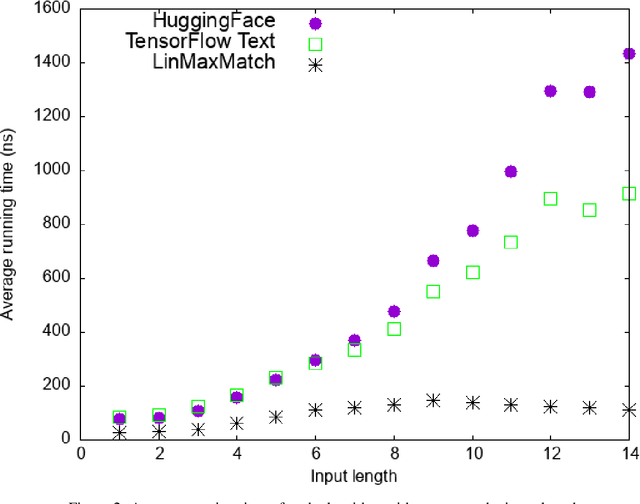
WordPiece tokenization is a subword-based tokenization schema adopted by BERT: it segments the input text via a longest-match-first tokenization strategy, known as Maximum Matching or MaxMatch. To the best of our knowledge, all published MaxMatch algorithms are quadratic (or higher). In this paper, we propose LinMaxMatch, a novel linear-time algorithm for MaxMatch and WordPiece tokenization. Inspired by the Aho-Corasick algorithm, we introduce additional linkages on top of the trie built from the vocabulary, allowing smart transitions when the trie matching cannot continue. Experimental results show that our algorithm is 3x faster on average than two production systems by HuggingFace and TensorFlow Text. Regarding long-tail inputs, our algorithm is 4.5x faster at the 95 percentile. This work has immediate practical value (reducing inference latency, saving compute resources, etc.) and is of theoretical interest by providing an optimal complexity solution to the decades-old MaxMatch problem.