 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Dropping for Efficient BERT Pretraining
Paper and Code

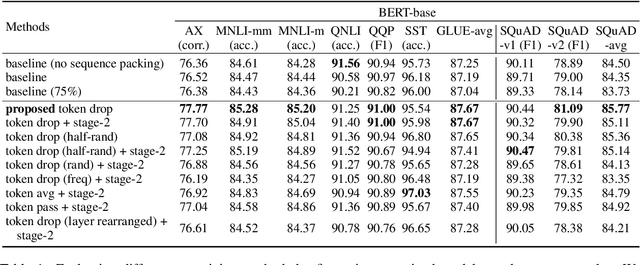
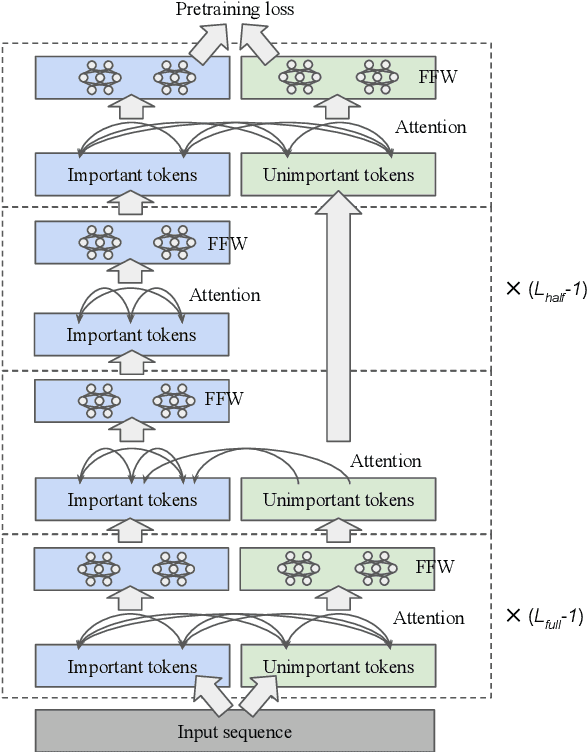
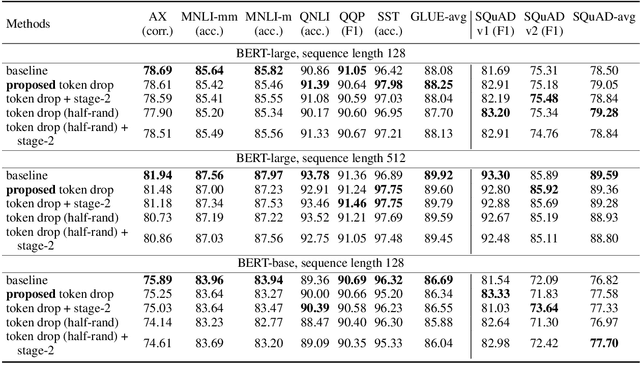
Transformer-based models generally allocate the same amount of computation for each token in a given sequence. We develop a simple but effective "token dropping" method to accelerate the pretraining of transformer models, such as BERT, without degrading its performance on downstream tasks. In short, we drop unimportant tokens starting from an intermediate layer in the model to make the model focus on important tokens; the dropped tokens are later picked up by the last layer of the model so that the model still produces full-length sequences. We leverage the already built-in masked language modeling (MLM) loss to identify unimportant tokens with practically no computational overhead. In our experiments, this simple approach reduces the pretraining cost of BERT by 25% while achieving similar overall fine-tuning performance on standard downstream tasks.