 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVESTA: A Fully Automated Scenario Generation and Safety Evaluation Framework for LLM Agents
Jun 07, 2026Large language models (LLMs) are increasingly evolving from simple text-based interaction systems into LLM agents that can maintain memory, use tools, access external environments, and execute tasks. As their capabilities and autonomy expand, the safety risks they face also become more diverse. Existing evaluations often rely on manually written scenarios, static prompts, or final-output judgments, making it difficult to capture the diverse risks that agents may face during task execution. We introduce VESTA, a fully automated scenario generation and safety evaluation framework for LLM agents. Based on five risk dimensions, VESTA instantiaes abstract and diverse safety risks in real-world task execution into 1,072 measurable evaluation scenarios. Using the automated evaluation pipeline, 12 LLM agents are evaluated under two authority contexts. The results show that current agents still face substantial behavioral safety risks during task execution, with an average ASR of 47.1% and several models exceeding 70%. These findings demonstrate the importance of executable, process-level evaluation for understanding and improving LLM agent safety.
K-Gen: A Multimodal Language-Conditioned Approach for Interpretable Keypoint-Guided Trajectory Generation
Mar 05, 2026Generating realistic and diverse trajectories is a critical challenge in autonomous driving simulation. While Large Language Models (LLMs) show promise, existing methods often rely on structured data like vectorized maps, which fail to capture the rich, unstructured visual context of a scene. To address this, we propose K-Gen, an interpretable keypoint-guided multimodal framework that leverages Multimodal Large Language Models (MLLMs) to unify rasterized BEV map inputs with textual scene descriptions. Instead of directly predicting full trajectories, K-Gen generates interpretable keypoints along with reasoning that reflects agent intentions, which are subsequently refined into accurate trajectories by a refinement module. To further enhance keypoint generation, we apply T-DAPO, a trajectory-aware reinforcement fine-tuning algorithm. Experiments on WOMD and nuPlan demonstrate that K-Gen outperforms existing baselines, highlighting the effectiveness of combining multimodal reasoning with keypoint-guided trajectory generation.
ForesightSafety Bench: A Frontier Risk Evaluation and Governance Framework towards Safe AI
Feb 15, 2026Rapidly evolving AI exhibits increasingly strong autonomy and goal-directed capabilities, accompanied by derivative systemic risks that are more unpredictable, difficult to control, and potentially irreversible. However, current AI safety evaluation systems suffer from critical limitations such as restricted risk dimensions and failed frontier risk detection. The lagging safety benchmarks and alignment technologies can hardly address the complex challenges posed by cutting-edge AI models. To bridge this gap, we propose the "ForesightSafety Bench" AI Safety Evaluation Framework, beginning with 7 major Fundamental Safety pillars and progressively extends to advanced Embodied AI Safety, AI4Science Safety, Social and Environmental AI risks, Catastrophic and Existential Risks, as well as 8 critical industrial safety domains, forming a total of 94 refined risk dimensions. To date, the benchmark has accumulated tens of thousands of structured risk data points and assessment results, establishing a widely encompassing, hierarchically clear, and dynamically evolving AI safety evaluation framework. Based on this benchmark, we conduct systematic evaluation and in-depth analysis of over twenty mainstream advanced large models, identifying key risk patterns and their capability boundaries. The safety capability evaluation results reveals the widespread safety vulnerabilities of frontier AI across multiple pillars, particularly focusing on Risky Agentic Autonomy, AI4Science Safety, Embodied AI Safety, Social AI Safety and Catastrophic and Existential Risks. Our benchmark is released at https://github.com/Beijing-AISI/ForesightSafety-Bench. The project website is available at https://foresightsafety-bench.beijing-aisi.ac.cn/.
Batch Bayesian Optimization via Expected Subspace Improvement
Nov 25, 2024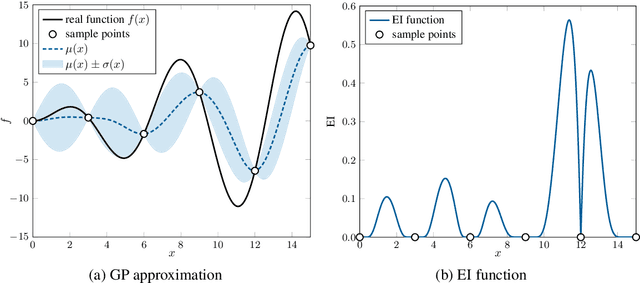



Extending Bayesian optimization to batch evaluation can enable the designer to make the most use of parallel computing technology. Most of current batch approaches use artificial functions to simulate the sequential Bayesian optimization algorithm's behavior to select a batch of points for parallel evaluation. However, as the batch size grows, the accumulated error introduced by these artificial functions increases rapidly, which dramatically decreases the optimization efficiency of the algorithm. In this work, we propose a simple and efficient approach to extend Bayesian optimization to batch evaluation. Different from existing batch approaches, the idea of the new approach is to draw a batch of subspaces of the original problem and select one acquisition point from each subspace. To achieve this, we propose the expected subspace improvement criterion to measure the amount of the improvement that a candidate point can achieve within a certain subspace. By optimizing these expected subspace improvement functions simultaneously, we can get a batch of query points for expensive evaluation. Numerical experiments show that our proposed approach can achieve near-linear speedup when compared with the sequential Bayesian optimization algorithm, and performs very competitively when compared with eight state-of-the-art batch algorithms. This work provides a simple yet efficient approach for batch Bayesian optimization. A Matlab implementation of our approach is available at https://github.com/zhandawei/Expected_Subspace_Improvement_Batch_Bayesian_Optimization
Anomaly Correction of Business Processes Using Transformer Autoencoder
Apr 16, 2024



Event log records all events that occur during the execution of business processes, so detecting and correcting anomalies in event log can provide reliable guarantee for subsequent process analysis. The previous works mainly include next event prediction based methods and autoencoder-based methods. These methods cannot accurately and efficiently detect anomalies and correct anomalies at the same time, and they all rely on the set threshold to detect anomalies. To solve these problems, we propose a business process anomaly correction method based on Transformer autoencoder. By using self-attention mechanism and autoencoder structure, it can efficiently process event sequences of arbitrary length, and can directly output corrected business process instances, so that it can adapt to various scenarios. At the same time, the anomaly detection is transformed into a classification problem by means of selfsupervised learning, so that there is no need to set a specific threshold in anomaly detection. The experimental results on several real-life event logs show that the proposed method is superior to the previous methods in terms of anomaly detection accuracy and anomaly correction results while ensuring high running efficiency.
Online Sequential Decision-Making with Unknown Delays
Feb 23, 2024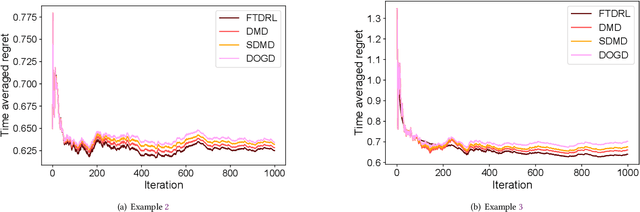
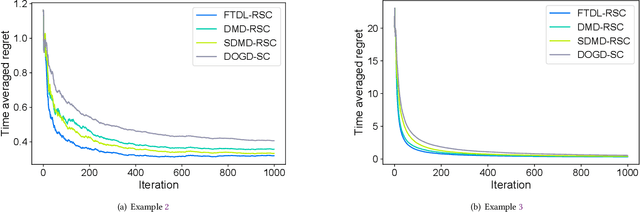
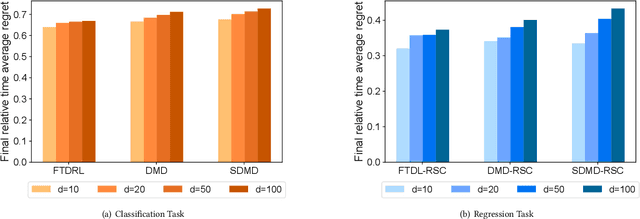
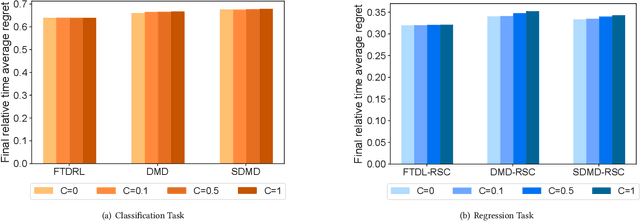
In the field of online sequential decision-making, we address the problem with delays utilizing the framework of online convex optimization (OCO), where the feedback of a decision can arrive with an unknown delay. Unlike previous research that is limited to Euclidean norm and gradient information, we propose three families of delayed algorithms based on approximate solutions to handle different types of received feedback. Our proposed algorithms are versatile and applicable to universal norms. Specifically, we introduce a family of Follow the Delayed Regularized Leader algorithms for feedback with full information on the loss function, a family of Delayed Mirror Descent algorithms for feedback with gradient information on the loss function and a family of Simplified Delayed Mirror Descent algorithms for feedback with the value information of the loss function's gradients at corresponding decision points. For each type of algorithm, we provide corresponding regret bounds under cases of general convexity and relative strong convexity, respectively. We also demonstrate the efficiency of each algorithm under different norms through concrete examples. Furthermore, our theoretical results are consistent with the current best bounds when degenerated to standard settings.
A Fully-Automatic Framework for Parkinson's Disease Diagnosis by Multi-Modality Images
Feb 26, 2019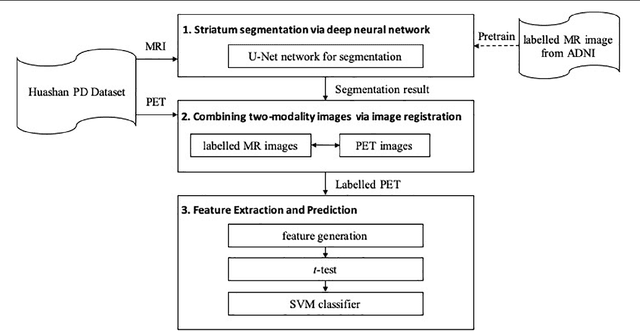
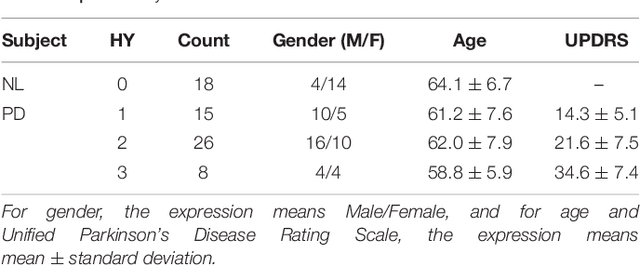
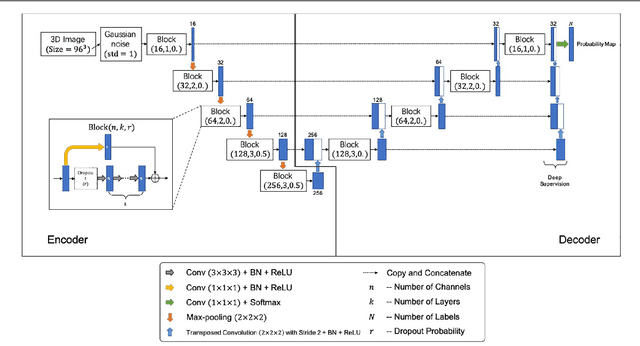
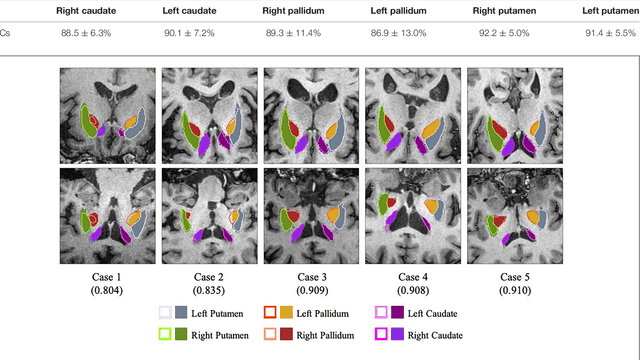
Background: Parkinson's disease (PD) is a prevalent long-term neurodegenerative disease. Though the diagnostic criteria of PD are relatively well defined, the current medical imaging diagnostic procedures are expertise-demanding, and thus call for a higher-integrated AI-based diagnostic algorithm. Methods: In this paper, we proposed an automatic, end-to-end, multi-modality diagnosis framework, including segmentation, registration, feature generation and machine learning, to process the information of the striatum for the diagnosis of PD. Multiple modalities, including T1- weighted MRI and 11C-CFT PET, were used in the proposed framework. The reliability of this framework was then validated on a dataset from the PET center of Huashan Hospital, as the dataset contains paired T1-MRI and CFT-PET images of 18 Normal (NL) subjects and 49 PD subjects. Results: We obtained an accuracy of 100% for the PD/NL classification task, besides, we conducted several comparative experiments to validate the diagnosis ability of our framework. Conclusion: Through experiment we illustrate that (1) automatic segmentation has the same classification effect as the manual segmentation, (2) the multi-modality images generates a better prediction than single modality images, and (3) volume feature is shown to be irrelevant to PD diagnosis.
Learning Optimal Deep Projection of $^{18}$F-FDG PET Imaging for Early Differential Diagnosis of Parkinsonian Syndromes
Oct 11, 2018


Several diseases of parkinsonian syndromes present similar symptoms at early stage and no objective widely used diagnostic methods have been approved until now. Positron emission tomography (PET) with $^{18}$F-FDG was shown to be able to assess early neuronal dysfunction of synucleinopathies and tauopathies. Tensor factorization (TF) based approaches have been applied to identify characteristic metabolic patterns for differential diagnosis. However, these conventional dimension-reduction strategies assume linear or multi-linear relationships inside data, and are therefore insufficient to distinguish nonlinear metabolic differences between various parkinsonian syndromes. In this paper, we propose a Deep Projection Neural Network (DPNN) to identify characteristic metabolic pattern for early differential diagnosis of parkinsonian syndromes. We draw our inspiration from the existing TF methods. The network consists of a (i) compression part: which uses a deep network to learn optimal 2D projections of 3D scans, and a (ii) classification part: which maps the 2D projections to labels. The compression part can be pre-trained using surplus unlabelled datasets. Also, as the classification part operates on these 2D projections, it can be trained end-to-end effectively with limited labelled data, in contrast to 3D approaches. We show that DPNN is more effective in comparison to existing state-of-the-art and plausible baselines.
* 8 pages, 3 figures, conference, MICCAI DLMIA, 2018