 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Performance Improvement of Tensor Processing Engines through Transformation in the Bit-weight Dimension of MACs
Mar 08, 2025General matrix-matrix multiplication (GEMM) is a cornerstone of AI computations, making tensor processing engines (TPEs) increasingly critical in GPUs and domain-specific architectures. Existing architectures primarily optimize dataflow or operand reuse strategies. However, considering the interaction between matrix multiplication and multiply-accumulators (MACs) offers greater optimization potential. This work introduces a novel hardware perspective on matrix multiplication, focusing on the bit-weight dimension of MACs. We propose a finer-grained TPE notation using matrix triple loops as an example, introducing new methods for designing and optimizing PE microarchitectures. Based on this notation and its transformations, we propose four optimization techniques that improve timing, area, and power consumption. Implementing our design in RTL using the SMIC-28nm process, we evaluate its effectiveness across four classic TPE architectures: systolic array, 3D-Cube, multiplier-adder tree, and 2D-Matrix. Our techniques achieve area efficiency improvements of 1.27x, 1.28x, 1.56x, and 1.44x, and energy efficiency gains of 1.04x, 1.56x, 1.49x, and 1.20x, respectively. Applied to a bit-slice architecture, our approach achieves a 12.10x improvement in energy efficiency and 2.85x in area efficiency compared to Laconic. Our Verilog HDL code, along with timing, area, and power reports, is available at https://github.com/wqzustc/High-Performance-Tensor-Processing-Engines
Batch Bayesian Optimization via Expected Subspace Improvement
Nov 25, 2024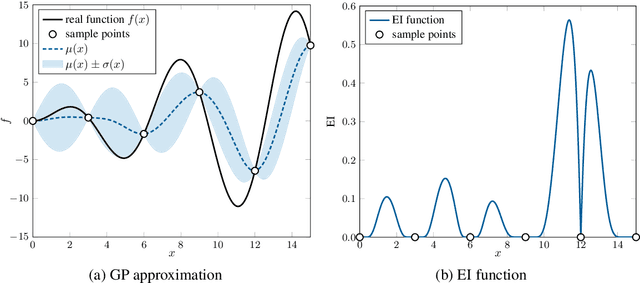



Extending Bayesian optimization to batch evaluation can enable the designer to make the most use of parallel computing technology. Most of current batch approaches use artificial functions to simulate the sequential Bayesian optimization algorithm's behavior to select a batch of points for parallel evaluation. However, as the batch size grows, the accumulated error introduced by these artificial functions increases rapidly, which dramatically decreases the optimization efficiency of the algorithm. In this work, we propose a simple and efficient approach to extend Bayesian optimization to batch evaluation. Different from existing batch approaches, the idea of the new approach is to draw a batch of subspaces of the original problem and select one acquisition point from each subspace. To achieve this, we propose the expected subspace improvement criterion to measure the amount of the improvement that a candidate point can achieve within a certain subspace. By optimizing these expected subspace improvement functions simultaneously, we can get a batch of query points for expensive evaluation. Numerical experiments show that our proposed approach can achieve near-linear speedup when compared with the sequential Bayesian optimization algorithm, and performs very competitively when compared with eight state-of-the-art batch algorithms. This work provides a simple yet efficient approach for batch Bayesian optimization. A Matlab implementation of our approach is available at https://github.com/zhandawei/Expected_Subspace_Improvement_Batch_Bayesian_Optimization