 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePtychographic non-line-of-sight imaging for depth-resolved visualization of hidden objects
May 17, 2024



Non-line-of-sight (NLOS) imaging enables the visualization of objects hidden from direct view, with applications in surveillance, remote sensing, and light detection and ranging. Here, we introduce a NLOS imaging technique termed ptychographic NLOS (pNLOS), which leverages coded ptychography for depth-resolved imaging of obscured objects. Our approach involves scanning a laser spot on a wall to illuminate the hidden objects in an obscured region. The reflected wavefields from these objects then travel back to the wall, get modulated by the wall's complex-valued profile, and the resulting diffraction patterns are captured by a camera. By modulating the object wavefields, the wall surface serves the role of the coded layer as in coded ptychography. As we scan the laser spot to different positions, the reflected object wavefields on the wall translate accordingly, with the shifts varying for objects at different depths. This translational diversity enables the acquisition of a set of modulated diffraction patterns referred to as a ptychogram. By processing the ptychogram, we recover both the objects at different depths and the modulation profile of the wall surface. Experimental results demonstrate high-resolution, high-fidelity imaging of hidden objects, showcasing the potential of pNLOS for depth-aware vision beyond the direct line of sight.
COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning
Mar 26, 2024
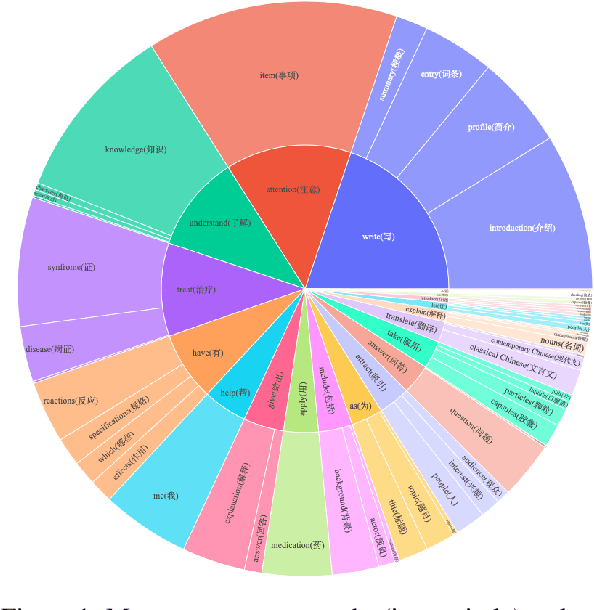
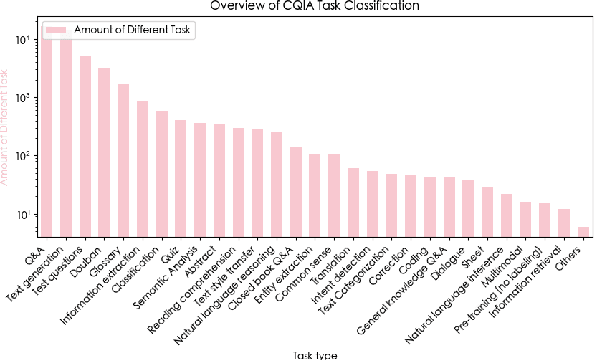

Recently, there have been significant advancements in large language models (LLMs), particularly focused on the English language. These advancements have enabled these LLMs to understand and execute complex instructions with unprecedented accuracy and fluency. However, despite these advancements, there remains a noticeable gap in the development of Chinese instruction tuning. The unique linguistic features and cultural depth of the Chinese language pose challenges for instruction tuning tasks. Existing datasets are either derived from English-centric LLMs or are ill-suited for aligning with the interaction patterns of real-world Chinese users. To bridge this gap, we introduce COIG-CQIA, a high-quality Chinese instruction tuning dataset. Our aim is to build a diverse, wide-ranging instruction-tuning dataset to better align model behavior with human interactions. To this end, we collect a high-quality human-written corpus from various sources on the Chinese Internet, including Q&A communities, Wikis, examinations, and existing NLP datasets. This corpus was rigorously filtered and carefully processed to form the COIG-CQIA dataset. Furthermore, we train models of various scales on different subsets of CQIA, following in-depth evaluation and analyses. The findings from our experiments offer valuable insights for selecting and developing Chinese instruction-tuning datasets. We also find that models trained on CQIA-Subset achieve competitive results in human assessment as well as knowledge and security benchmarks. Data are available at https://huggingface.co/datasets/m-a-p/COIG-CQIA