 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMessIRve: A Large-Scale Spanish Information Retrieval Dataset
Paper and Code

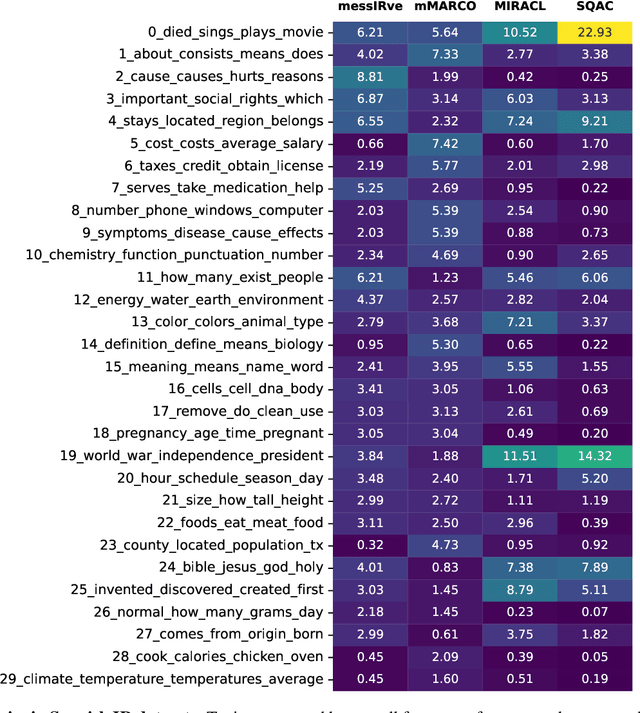

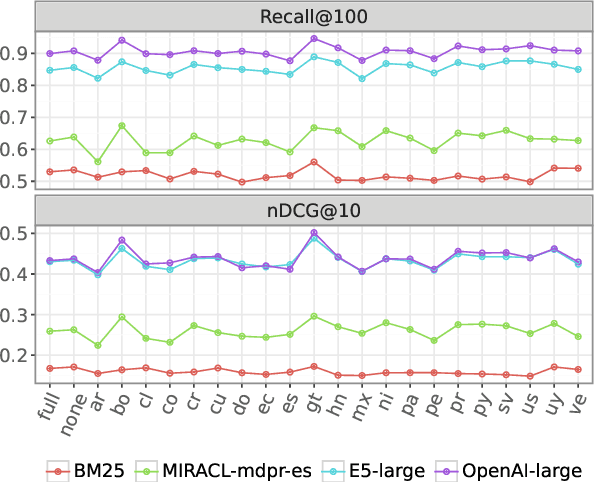
Information retrieval (IR) is the task of finding relevant documents in response to a user query. Although Spanish is the second most spoken native language, current IR benchmarks lack Spanish data, hindering the development of information access tools for Spanish speakers. We introduce MessIRve, a large-scale Spanish IR dataset with around 730 thousand queries from Google's autocomplete API and relevant documents sourced from Wikipedia. MessIRve's queries reflect diverse Spanish-speaking regions, unlike other datasets that are translated from English or do not consider dialectal variations. The large size of the dataset allows it to cover a wide variety of topics, unlike smaller datasets. We provide a comprehensive description of the dataset, comparisons with existing datasets, and baseline evaluations of prominent IR models. Our contributions aim to advance Spanish IR research and improve information access for Spanish speakers.