 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Multi-Agent Coordination Abilities in Large Language Models
Paper and Code
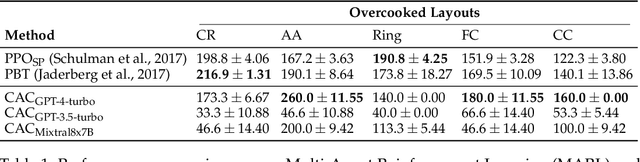
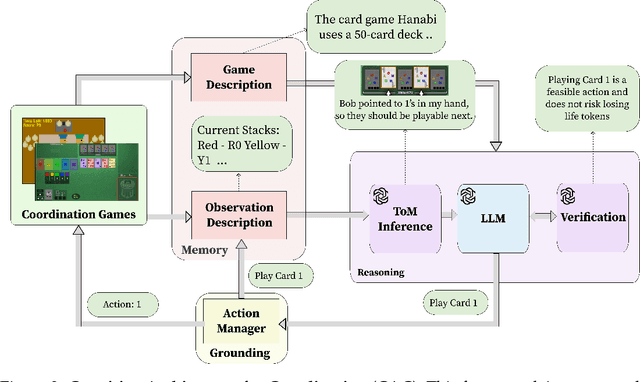

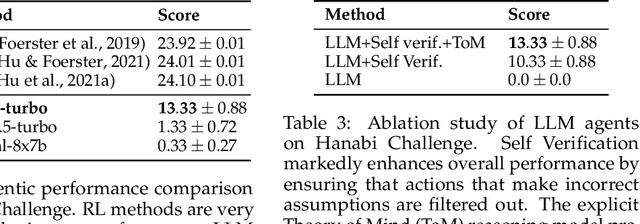
A pivotal aim in contemporary AI research is to develop agents proficient in multi-agent coordination, enabling effective collaboration with both humans and other systems. Large Language Models (LLMs), with their notable ability to understand, generate, and interpret language in a human-like manner, stand out as promising candidates for the development of such agents. In this study, we build and assess the effectiveness of agents crafted using LLMs in various coordination scenarios. We introduce the LLM-Coordination (LLM-Co) Framework, specifically designed to enable LLMs to play coordination games. With the LLM-Co framework, we conduct our evaluation with three game environments and organize the evaluation into five aspects: Theory of Mind, Situated Reasoning, Sustained Coordination, Robustness to Partners, and Explicit Assistance. First, the evaluation of the Theory of Mind and Situated Reasoning reveals the capabilities of LLM to infer the partner's intention and reason actions accordingly. Then, the evaluation around Sustained Coordination and Robustness to Partners further showcases the ability of LLMs to coordinate with an unknown partner in complex long-horizon tasks, outperforming Reinforcement Learning baselines. Lastly, to test Explicit Assistance, which refers to the ability of an agent to offer help proactively, we introduce two novel layouts into the Overcooked-AI benchmark, examining if agents can prioritize helping their partners, sacrificing time that could have been spent on their tasks. This research underscores the promising capabilities of LLMs in sophisticated coordination environments and reveals the potential of LLMs in building strong real-world agents for multi-agent coordination.