 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneRanker: Unified Generation and Ranking with One Model in Industrial Advertising Recommendation
Mar 04, 2026The end-to-end generative paradigm is revolutionizing advertising recommendation systems, driving a shift from traditional cascaded architectures towards unified modeling. However, practical deployment faces three core challenges: the misalignment between interest objectives and business value, the target-agnostic limitation of generative processes, and the disconnection between generation and ranking stages. Existing solutions often fall into a dilemma where single-stage fusion induces optimization tension, while stage decoupling causes irreversible information loss. To address this, we propose OneRanker, achieving architectural-level deep integration of generation and ranking. First, we design a value-aware multi-task decoupling architecture. By leveraging task token sequences and causal mask, we separate interest coverage and value optimization spaces within shared representations, effectively alleviating target conflicts. Second, we construct a coarse-to-fine collaborative target awareness mechanism, utilizing Fake Item Tokens for implicit awareness during generation and a ranking decoder for explicit value alignment at the candidate level. Finally, we propose input-output dual-side consistency guarantees. Through Key/Value pass-through mechanisms and Distribution Consistency (DC) Constraint Loss, we achieve end-to-end collaborative optimization between generation and ranking. The full deployment on Tencent's WeiXin channels advertising system has shown a significant improvement in key business metrics (GMV - Normal +1.34\%), providing a new paradigm with industrial feasibility for generative advertising recommendations.
Chinese SimpleQA: A Chinese Factuality Evaluation for Large Language Models
Nov 13, 2024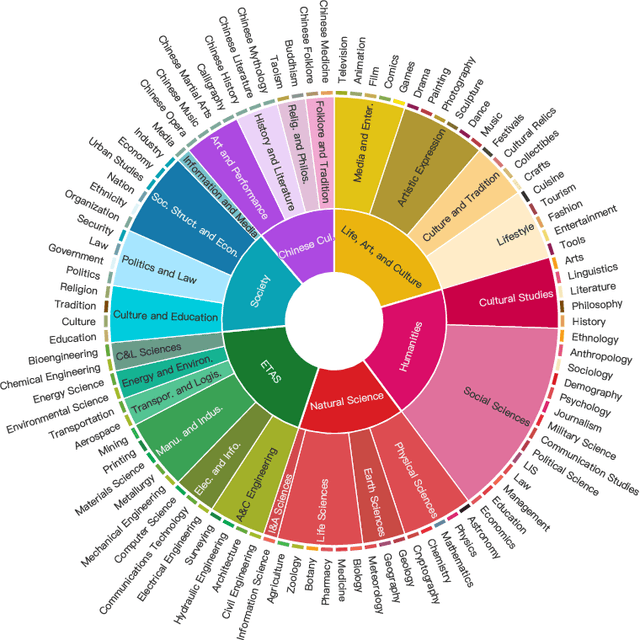


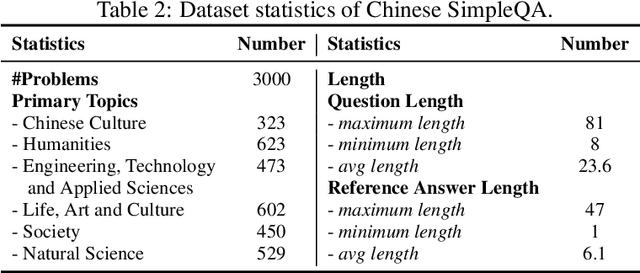
New LLM evaluation benchmarks are important to align with the rapid development of Large Language Models (LLMs). In this work, we present Chinese SimpleQA, the first comprehensive Chinese benchmark to evaluate the factuality ability of language models to answer short questions, and Chinese SimpleQA mainly has five properties (i.e., Chinese, Diverse, High-quality, Static, Easy-to-evaluate). Specifically, first, we focus on the Chinese language over 6 major topics with 99 diverse subtopics. Second, we conduct a comprehensive quality control process to achieve high-quality questions and answers, where the reference answers are static and cannot be changed over time. Third, following SimpleQA, the questions and answers are very short, and the grading process is easy-to-evaluate based on OpenAI API. Based on Chinese SimpleQA, we perform a comprehensive evaluation on the factuality abilities of existing LLMs. Finally, we hope that Chinese SimpleQA could guide the developers to better understand the Chinese factuality abilities of their models and facilitate the growth of foundation models.
Using Auxiliary Tasks In Multimodal Fusion Of Wav2vec 2.0 And BERT For Multimodal Emotion Recognition
Feb 27, 2023The lack of data and the difficulty of multimodal fusion have always been challenges for multimodal emotion recognition (MER). In this paper, we propose to use pretrained models as upstream network, wav2vec 2.0 for audio modality and BERT for text modality, and finetune them in downstream task of MER to cope with the lack of data. For the difficulty of multimodal fusion, we use a K-layer multi-head attention mechanism as a downstream fusion module. Starting from the MER task itself, we design two auxiliary tasks to alleviate the insufficient fusion between modalities and guide the network to capture and align emotion-related features. Compared to the previous state-of-the-art models, we achieve a better performance by 78.42% Weighted Accuracy (WA) and 79.71% Unweighted Accuracy (UA) on the IEMOCAP dataset.