 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Factorization for Speech Signal
Paper and Code
Jun 25, 2017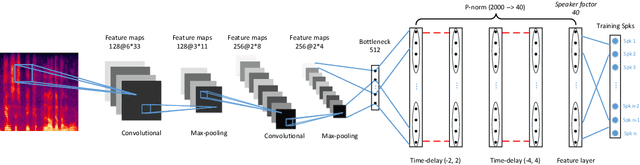
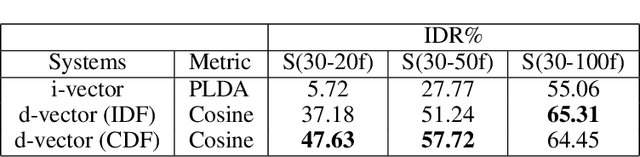
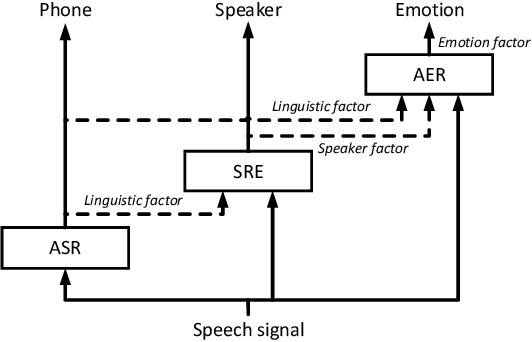
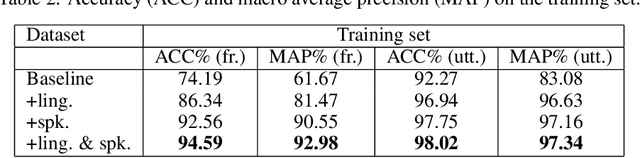
Speech signals are complex intermingling of various informative factors, and this information blending makes decoding any of the individual factors extremely difficult. A natural idea is to factorize each speech frame into independent factors, though it turns out to be even more difficult than decoding each individual factor. A major encumbrance is that the speaker trait, a major factor in speech signals, has been suspected to be a long-term distributional pattern and so not identifiable at the frame level. In this paper, we demonstrated that the speaker factor is also a short-time spectral pattern and can be largely identified with just a few frames using a simple deep neural network (DNN). This discovery motivated a cascade deep factorization (CDF) framework that infers speech factors in a sequential way, and factors previously inferred are used as conditional variables when inferring other factors. Our experiment on an automatic emotion recognition (AER) task demonstrated that this approach can effectively factorize speech signals, and using these factors, the original speech spectrum can be recovered with high accuracy. This factorization and reconstruction approach provides a novel tool for many speech processing tasks.