 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKDExplainer: A Task-oriented Attention Model for Explaining Knowledge Distillation
Paper and Code
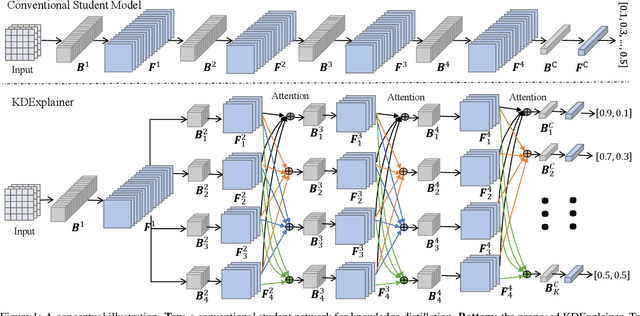
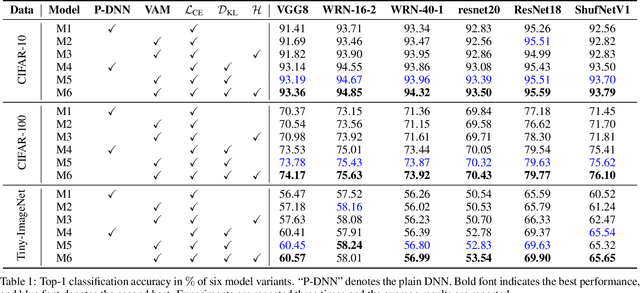
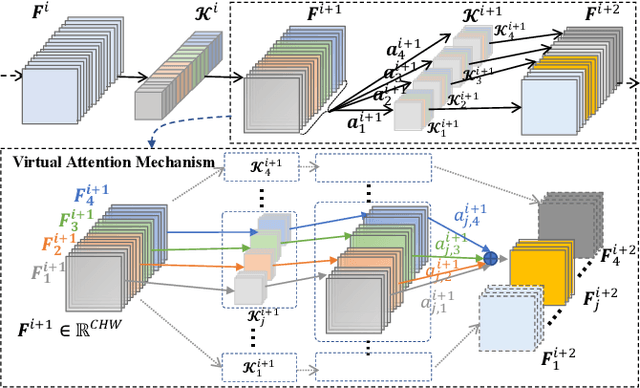
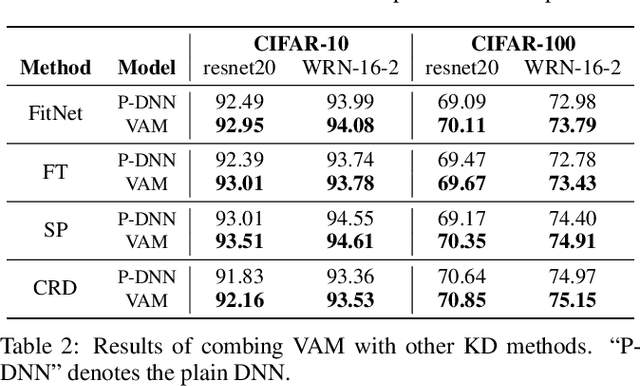
Knowledge distillation (KD) has recently emerged as an efficacious scheme for learning compact deep neural networks (DNNs). Despite the promising results achieved, the rationale that interprets the behavior of KD has yet remained largely understudied. In this paper, we introduce a novel task-oriented attention model, termed as KDExplainer, to shed light on the working mechanism underlying the vanilla KD. At the heart of KDExplainer is a Hierarchical Mixture of Experts (HME), in which a multi-class classification is reformulated as a multi-task binary one. Through distilling knowledge from a free-form pre-trained DNN to KDExplainer, we observe that KD implicitly modulates the knowledge conflicts between different subtasks, and in reality has much more to offer than label smoothing. Based on such findings, we further introduce a portable tool, dubbed as virtual attention module (VAM), that can be seamlessly integrated with various DNNs to enhance their performance under KD. Experimental results demonstrate that with a negligible additional cost, student models equipped with VAM consistently outperform their non-VAM counterparts across different benchmarks. Furthermore, when combined with other KD methods, VAM remains competent in promoting results, even though it is only motivated by vanilla KD. The code is available at https://github.com/zju-vipa/KDExplainer.