 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Sample Selection Strategies for Large Language Model Repair
Oct 23, 2025Large language models (LLMs) are increasingly deployed in real-world systems, yet they can produce toxic or biased outputs that undermine safety and trust. Post-hoc model repair provides a practical remedy, but the high cost of parameter updates motivates selective use of repair data. Despite extensive prior work on data selection for model training, it remains unclear which sampling criteria are most effective and efficient when applied specifically to behavioral repair of large generative models. Our study presents a systematic analysis of sample prioritization strategies for LLM repair. We evaluate five representative selection methods, including random sampling, K-Center, gradient-norm-based selection(GraNd), stratified coverage (CCS), and a Semantic-Aware Prioritized Sampling (SAPS) approach we proposed. Repair effectiveness and trade-offs are assessed through toxicity reduction, perplexity on WikiText-2 and LAMBADA, and three composite metrics: the Repair Proximity Score (RPS), the Overall Performance Score (OPS), and the Repair Efficiency Score (RES). Experimental results show that SAPS achieves the best balance between detoxification, utility preservation, and efficiency, delivering comparable or superior repair outcomes with substantially less data. Random sampling remains effective for large or robust models, while high-overhead methods such as CCS and GraNd provide limited benefit. The optimal data proportion depends on model scale and repair method, indicating that sample selection should be regarded as a tunable component of repair pipelines. Overall, these findings establish selection-based repair as an efficient and scalable paradigm for maintaining LLM reliability.
PRUNE: A Patching Based Repair Framework for Certiffable Unlearning of Neural Networks
May 10, 2025It is often desirable to remove (a.k.a. unlearn) a speciffc part of the training data from a trained neural network model. A typical application scenario is to protect the data holder's right to be forgotten, which has been promoted by many recent regulation rules. Existing unlearning methods involve training alternative models with remaining data, which may be costly and challenging to verify from the data holder or a thirdparty auditor's perspective. In this work, we provide a new angle and propose a novel unlearning approach by imposing carefully crafted "patch" on the original neural network to achieve targeted "forgetting" of the requested data to delete. Speciffcally, inspired by the research line of neural network repair, we propose to strategically seek a lightweight minimum "patch" for unlearning a given data point with certiffable guarantee. Furthermore, to unlearn a considerable amount of data points (or an entire class), we propose to iteratively select a small subset of representative data points to unlearn, which achieves the effect of unlearning the whole set. Extensive experiments on multiple categorical datasets demonstrates our approach's effectiveness, achieving measurable unlearning while preserving the model's performance and being competitive in efffciency and memory consumption compared to various baseline methods.
The Double-Edged Sword of Input Perturbations to Robust Accurate Fairness
Apr 01, 2024Deep neural networks (DNNs) are known to be sensitive to adversarial input perturbations, leading to a reduction in either prediction accuracy or individual fairness. To jointly characterize the susceptibility of prediction accuracy and individual fairness to adversarial perturbations, we introduce a novel robustness definition termed robust accurate fairness. Informally, robust accurate fairness requires that predictions for an instance and its similar counterparts consistently align with the ground truth when subjected to input perturbations. We propose an adversarial attack approach dubbed RAFair to expose false or biased adversarial defects in DNN, which either deceive accuracy or compromise individual fairness. Then, we show that such adversarial instances can be effectively addressed by carefully designed benign perturbations, correcting their predictions to be accurate and fair. Our work explores the double-edged sword of input perturbations to robust accurate fairness in DNN and the potential of using benign perturbations to correct adversarial instances.
Privacy and Security in Ubiquitous Integrated Sensing and Communication: Threats, Challenges and Future Directions
Aug 05, 2023Integrated sensing and communication (ISAC) technology is one of the featuring technologies of the next-generation communication systems. When sensing capability becomes ubiquitous, more information can be collected, which can facilitate many applications in intelligent transportation, unmanned aerial vehicle (UAV) surveillance and healthcare. However, it also faces many information privacy leakage and security issues. This article highlights the potential threats to privacy and security and the technical challenges to realizing private and secure ISAC. Three promising combating solutions including artificial intelligence (AI)-enabled schemes, friendly jamming and reconfigurable intelligent surface (RIS)-assisted design are provided to maintain user privacy and ensure information security. Case studies demonstrate their effectiveness.
RobustFair: Adversarial Evaluation through Fairness Confusion Directed Gradient Search
May 18, 2023
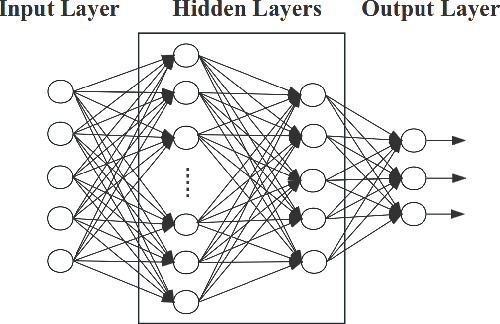
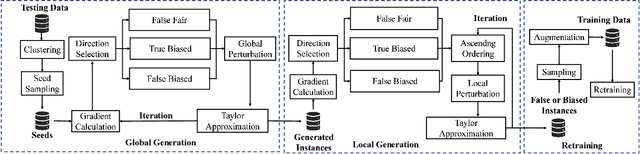
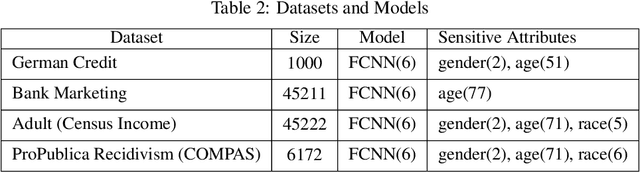
The trustworthiness of DNNs is often challenged by their vulnerability to minor adversarial perturbations, which may not only undermine prediction accuracy (robustness) but also cause biased predictions for similar inputs (individual fairness). Accurate fairness has been recently proposed to enforce a harmonic balance between accuracy and individual fairness. It induces the notion of fairness confusion matrix to categorize predictions as true fair, true biased, false fair, and false biased. This paper proposes a harmonic evaluation approach, RobustFair, for the accurate fairness of DNNs, using adversarial perturbations crafted through fairness confusion directed gradient search. By using Taylor expansions to approximate the ground truths of adversarial instances, RobustFair can particularly identify the robustness defects entangled for spurious fairness, which are often elusive in robustness evaluation, and missing in individual fairness evaluation. RobustFair can boost robustness and individual fairness evaluations by identifying robustness or fairness defects simultaneously. Empirical case studies on fairness benchmark datasets show that, compared with the state-of-the-art white-box robustness and individual fairness testing approaches, RobustFair detects significantly 1.77-11.87 times adversarial perturbations, yielding 1.83-13.12 times biased and 1.53-8.22 times false instances. The adversarial instances can then be effectively exploited to improve the accurate fairness (and hence accuracy and individual fairness) of the original deep neural network through retraining. The empirical case studies further show that the adversarial instances identified by RobustFair outperform those identified by the other testing approaches, in promoting 21% accurate fairness and 19% individual fairness on multiple sensitive attributes, without losing accuracy at all or even promoting it by up to 4%.
Accurate Fairness: Improving Individual Fairness without Trading Accuracy
May 18, 2022
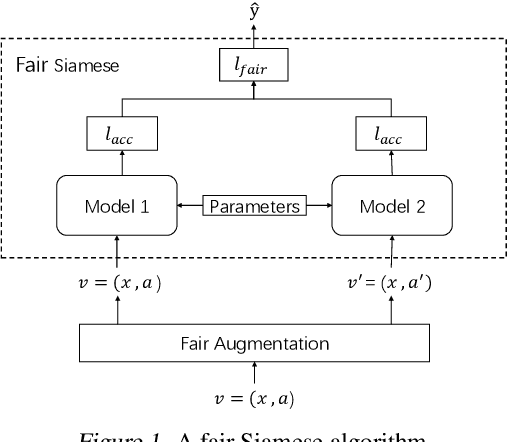
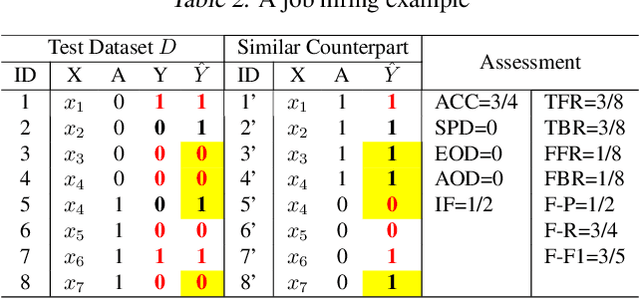
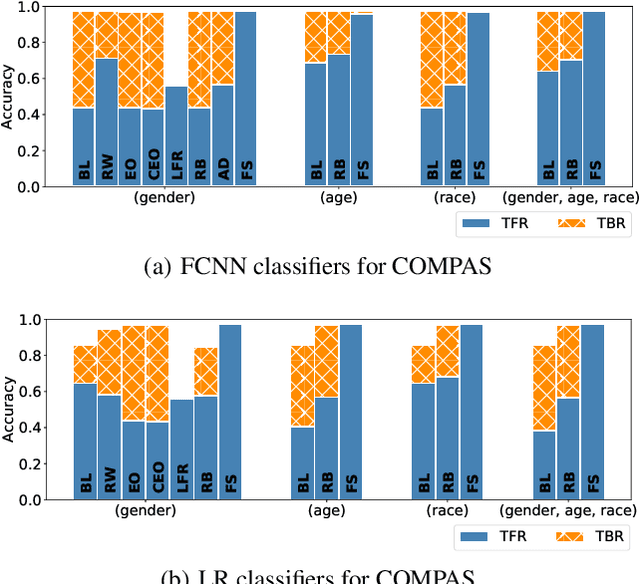
Accuracy and fairness are both crucial aspects for trustworthy machine learning. However, in practice, enhancing one aspect may sacrifice the other inevitably. We propose in this paper a new fairness criterion, accurate fairness, to assess whether an individual is treated both accurately and fairly regardless of protected attributes. We further propose new fairness metrics, fair-precision, fair-recall and fair-F1 score, to evaluate the reliability of a machine learning model from the perspective of accurate fairness. Thus, the side effects of enhancing just one of the two aspects, i.e., true bias and false fairness, can be effectively identified with our criterion. We then present a fair Siamese approach for accurate fairness training. To the best of our knowledge, this is the first time that a Siamese approach is adapted for bias mitigation. Case studies with typical fairness benchmarks demonstrate that our fair Siamese approach can, on average, promote the 17.4% higher individual fairness, the 11.5% higher fair-F1 score, and the 4.7% higher accuracy of a machine learning model than the state-of-the-art bias mitigation techniques. Finally, our approach is applied to mitigate the possible service discrimination with a real Ctrip dataset, by fairly serving on average 97.9% customers with different consumption habits who pay the same prices for the same rooms (20.7% more than original models).