 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Double-Edged Sword of Input Perturbations to Robust Accurate Fairness
Apr 01, 2024Deep neural networks (DNNs) are known to be sensitive to adversarial input perturbations, leading to a reduction in either prediction accuracy or individual fairness. To jointly characterize the susceptibility of prediction accuracy and individual fairness to adversarial perturbations, we introduce a novel robustness definition termed robust accurate fairness. Informally, robust accurate fairness requires that predictions for an instance and its similar counterparts consistently align with the ground truth when subjected to input perturbations. We propose an adversarial attack approach dubbed RAFair to expose false or biased adversarial defects in DNN, which either deceive accuracy or compromise individual fairness. Then, we show that such adversarial instances can be effectively addressed by carefully designed benign perturbations, correcting their predictions to be accurate and fair. Our work explores the double-edged sword of input perturbations to robust accurate fairness in DNN and the potential of using benign perturbations to correct adversarial instances.
RobustFair: Adversarial Evaluation through Fairness Confusion Directed Gradient Search
May 18, 2023
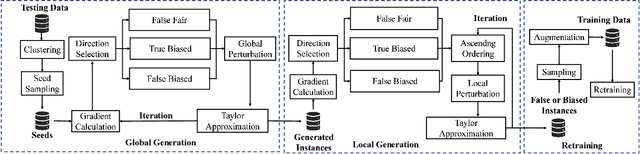
The trustworthiness of DNNs is often challenged by their vulnerability to minor adversarial perturbations, which may not only undermine prediction accuracy (robustness) but also cause biased predictions for similar inputs (individual fairness). Accurate fairness has been recently proposed to enforce a harmonic balance between accuracy and individual fairness. It induces the notion of fairness confusion matrix to categorize predictions as true fair, true biased, false fair, and false biased. This paper proposes a harmonic evaluation approach, RobustFair, for the accurate fairness of DNNs, using adversarial perturbations crafted through fairness confusion directed gradient search. By using Taylor expansions to approximate the ground truths of adversarial instances, RobustFair can particularly identify the robustness defects entangled for spurious fairness, which are often elusive in robustness evaluation, and missing in individual fairness evaluation. RobustFair can boost robustness and individual fairness evaluations by identifying robustness or fairness defects simultaneously. Empirical case studies on fairness benchmark datasets show that, compared with the state-of-the-art white-box robustness and individual fairness testing approaches, RobustFair detects significantly 1.77-11.87 times adversarial perturbations, yielding 1.83-13.12 times biased and 1.53-8.22 times false instances. The adversarial instances can then be effectively exploited to improve the accurate fairness (and hence accuracy and individual fairness) of the original deep neural network through retraining. The empirical case studies further show that the adversarial instances identified by RobustFair outperform those identified by the other testing approaches, in promoting 21% accurate fairness and 19% individual fairness on multiple sensitive attributes, without losing accuracy at all or even promoting it by up to 4%.