 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualSentinel: A Lightweight Framework for Detecting Targeted Attacks in Black-box LLM via Dual Entropy Lull Pattern
Mar 02, 2026Recent intelligent systems integrate powerful Large Language Models (LLMs) through APIs, but their trustworthiness may be critically undermined by targeted attacks like backdoor and prompt injection attacks, which secretly force LLMs to generate specific malicious sequences. Existing defensive approaches for such threats typically rely on high access rights, impose prohibitive costs, and hinder normal inference, rendering them impractical for real-world scenarios. To solve these limitations, we introduce DualSentinel, a lightweight and unified defense framework that can accurately and promptly detect the activation of targeted attacks alongside the LLM generation process. We first identify a characteristic of compromised LLMs, termed Entropy Lull: when a targeted attack successfully hijacks the generation process, the LLM exhibits a distinct period of abnormally low and stable token probability entropy, indicating it is following a fixed path rather than making creative choices. DualSentinel leverages this pattern by developing an innovative dual-check approach. It first employs a magnitude and trend-aware monitoring method to proactively and sensitively flag an entropy lull pattern at runtime. Upon such flagging, it triggers a lightweight yet powerful secondary verification based on task-flipping. An attack is confirmed only if the entropy lull pattern persists across both the original and the flipped task, proving that the LLM's output is coercively controlled. Extensive evaluations show that DualSentinel is both highly effective (superior detection accuracy with near-zero false positives) and remarkably efficient (negligible additional cost), offering a truly practical path toward securing deployed LLMs. The source code can be accessed at https://doi.org/10.5281/zenodo.18479273.
HALO: A Unified Vision-Language-Action Model for Embodied Multimodal Chain-of-Thought Reasoning
Feb 24, 2026Vision-Language-Action (VLA) models have shown strong performance in robotic manipulation, but often struggle in long-horizon or out-of-distribution scenarios due to the lack of explicit mechanisms for multimodal reasoning and anticipating how the world will evolve under action. Recent works introduce textual chain-of-thought or visual subgoal prediction within VLA models to reason, but still fail to offer a unified human-like reasoning framework for joint textual reasoning, visual foresight, and action prediction. To this end, we propose HALO, a unified VLA model that enables embodied multimodal chain-of-thought (EM-CoT) reasoning through a sequential process of textual task reasoning, visual subgoal prediction for fine-grained guidance, and EM-CoT-augmented action prediction. We instantiate HALO with a Mixture-of-Transformers (MoT) architecture that decouples semantic reasoning, visual foresight, and action prediction into specialized experts while allowing seamless cross-expert collaboration. To enable HALO learning at scale, we introduce an automated pipeline to synthesize EM-CoT training data along with a carefully crafted training recipe. Extensive experiments demonstrate that: (1) HALO achieves superior performance in both simulated and real-world environments, surpassing baseline policy pi_0 by 34.1% on RoboTwin benchmark; (2) all proposed components of the training recipe and EM-CoT design help improve task success rate; and (3) HALO exhibits strong generalization capabilities under aggressive unseen environmental randomization with our proposed EM-CoT reasoning.
TAP-ViTs: Task-Adaptive Pruning for On-Device Deployment of Vision Transformers
Jan 05, 2026Vision Transformers (ViTs) have demonstrated strong performance across a wide range of vision tasks, yet their substantial computational and memory demands hinder efficient deployment on resource-constrained mobile and edge devices. Pruning has emerged as a promising direction for reducing ViT complexity. However, existing approaches either (i) produce a single pruned model shared across all devices, ignoring device heterogeneity, or (ii) rely on fine-tuning with device-local data, which is often infeasible due to limited on-device resources and strict privacy constraints. As a result, current methods fall short of enabling task-customized ViT pruning in privacy-preserving mobile computing settings. This paper introduces TAP-ViTs, a novel task-adaptive pruning framework that generates device-specific pruned ViT models without requiring access to any raw local data. Specifically, to infer device-level task characteristics under privacy constraints, we propose a Gaussian Mixture Model (GMM)-based metric dataset construction mechanism. Each device fits a lightweight GMM to approximate its private data distribution and uploads only the GMM parameters. Using these parameters, the cloud selects distribution-consistent samples from public data to construct a task-representative metric dataset for each device. Based on this proxy dataset, we further develop a dual-granularity importance evaluation-based pruning strategy that jointly measures composite neuron importance and adaptive layer importance, enabling fine-grained, task-aware pruning tailored to each device's computational budget. Extensive experiments across multiple ViT backbones and datasets demonstrate that TAP-ViTs consistently outperforms state-of-the-art pruning methods under comparable compression ratios.
Generating Storytelling Images with Rich Chains-of-Reasoning
Dec 08, 2025An image can convey a compelling story by presenting rich, logically connected visual clues. These connections form Chains-of-Reasoning (CoRs) within the image, enabling viewers to infer events, causal relationships, and other information, thereby understanding the underlying story. In this paper, we focus on these semantically rich images and define them as Storytelling Images. Such images have diverse applications beyond illustration creation and cognitive screening, leveraging their ability to convey multi-layered information visually and inspire active interpretation. However, due to their complex semantic nature, Storytelling Images are inherently challenging to create, and thus remain relatively scarce. To address this challenge, we introduce the Storytelling Image Generation task, which explores how generative AI models can be leveraged to create such images. Specifically, we propose a two-stage pipeline, StorytellingPainter, which combines the creative reasoning abilities of Large Language Models (LLMs) with the visual synthesis capabilities of Text-to-Image (T2I) models to generate Storytelling Images. Alongside this pipeline, we develop a dedicated evaluation framework comprising three main evaluators: a Semantic Complexity Evaluator, a KNN-based Diversity Evaluator and a Story-Image Alignment Evaluator. Given the critical role of story generation in the Storytelling Image Generation task and the performance disparity between open-source and proprietary LLMs, we further explore tailored training strategies to reduce this gap, resulting in a series of lightweight yet effective models named Mini-Storytellers. Experimental results demonstrate the feasibility and effectiveness of our approaches. The code is available at https://github.com/xiujiesong/StorytellingImageGeneration.
AFLoRA: Adaptive Federated Fine-Tuning of Large Language Models with Resource-Aware Low-Rank Adaption
May 30, 2025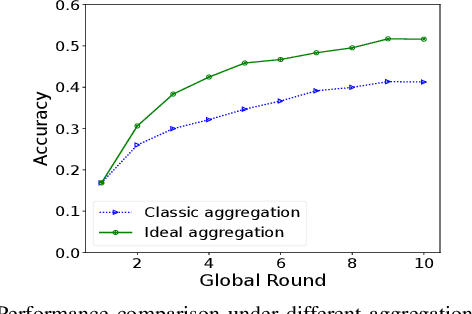
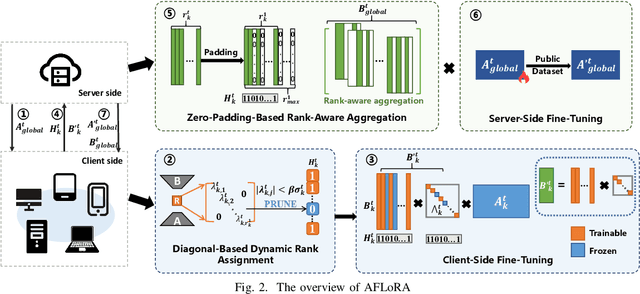
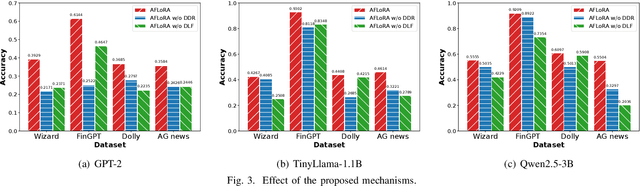
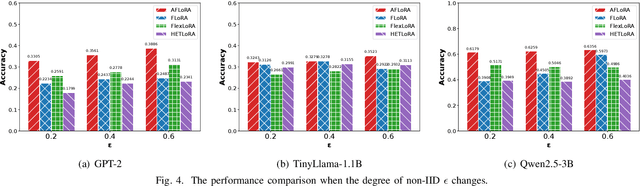
Federated fine-tuning has emerged as a promising approach to adapt foundation models to downstream tasks using decentralized data. However, real-world deployment remains challenging due to the high computational and communication demands of fine-tuning Large Language Models (LLMs) on clients with data and system resources that are heterogeneous and constrained. In such settings, the global model's performance is often bottlenecked by the weakest clients and further degraded by the non-IID nature of local data. Although existing methods leverage parameter-efficient techniques such as Low-Rank Adaptation (LoRA) to reduce communication and computation overhead, they often fail to simultaneously ensure accurate aggregation of low-rank updates and maintain low system costs, thereby hindering overall performance. To address these challenges, we propose AFLoRA, an adaptive and lightweight federated fine-tuning framework for LLMs. AFLoRA decouples shared and client-specific updates to reduce overhead and improve aggregation accuracy, incorporates diagonal matrix-based rank pruning to better utilize local resources, and employs rank-aware aggregation with public data refinement to strengthen generalization under data heterogeneity. Extensive experiments demonstrate that AFLoRA outperforms state-of-the-art methods in both accuracy and efficiency, providing a practical solution for efficient LLM adaptation in heterogeneous environments in the real world.
Is Your Image a Good Storyteller?
Dec 29, 2024Quantifying image complexity at the entity level is straightforward, but the assessment of semantic complexity has been largely overlooked. In fact, there are differences in semantic complexity across images. Images with richer semantics can tell vivid and engaging stories and offer a wide range of application scenarios. For example, the Cookie Theft picture is such a kind of image and is widely used to assess human language and cognitive abilities due to its higher semantic complexity. Additionally, semantically rich images can benefit the development of vision models, as images with limited semantics are becoming less challenging for them. However, such images are scarce, highlighting the need for a greater number of them. For instance, there is a need for more images like Cookie Theft to cater to people from different cultural backgrounds and eras. Assessing semantic complexity requires human experts and empirical evidence. Automatic evaluation of how semantically rich an image will be the first step of mining or generating more images with rich semantics, and benefit human cognitive assessment, Artificial Intelligence, and various other applications. In response, we propose the Image Semantic Assessment (ISA) task to address this problem. We introduce the first ISA dataset and a novel method that leverages language to solve this vision problem. Experiments on our dataset demonstrate the effectiveness of our approach. Our data and code are available at: https://github.com/xiujiesong/ISA.
Breaking Secure Aggregation: Label Leakage from Aggregated Gradients in Federated Learning
Jun 22, 2024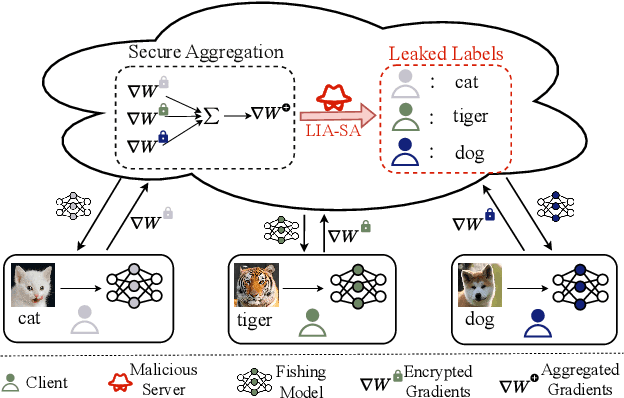
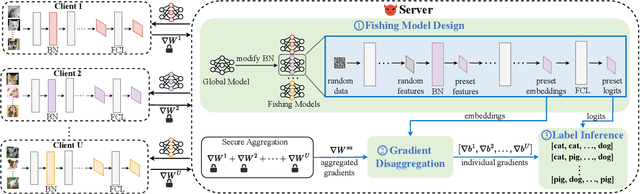
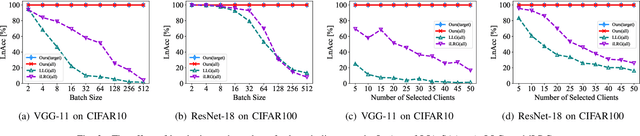
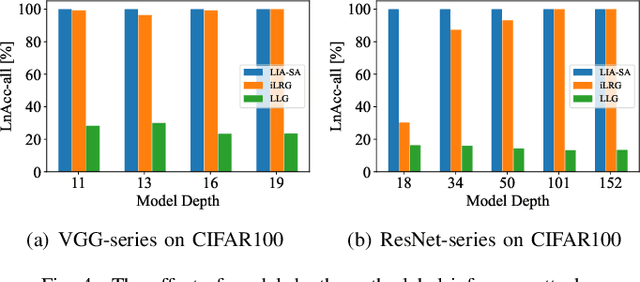
Federated Learning (FL) exhibits privacy vulnerabilities under gradient inversion attacks (GIAs), which can extract private information from individual gradients. To enhance privacy, FL incorporates Secure Aggregation (SA) to prevent the server from obtaining individual gradients, thus effectively resisting GIAs. In this paper, we propose a stealthy label inference attack to bypass SA and recover individual clients' private labels. Specifically, we conduct a theoretical analysis of label inference from the aggregated gradients that are exclusively obtained after implementing SA. The analysis results reveal that the inputs (embeddings) and outputs (logits) of the final fully connected layer (FCL) contribute to gradient disaggregation and label restoration. To preset the embeddings and logits of FCL, we craft a fishing model by solely modifying the parameters of a single batch normalization (BN) layer in the original model. Distributing client-specific fishing models, the server can derive the individual gradients regarding the bias of FCL by resolving a linear system with expected embeddings and the aggregated gradients as coefficients. Then the labels of each client can be precisely computed based on preset logits and gradients of FCL's bias. Extensive experiments show that our attack achieves large-scale label recovery with 100\% accuracy on various datasets and model architectures.