 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-SAM: Boosting Sharpness-Aware Minimization with Dominant-Eigenvector Gradient Correction
Jan 15, 2026Sharpness-Aware Minimization (SAM) aims to improve generalization by minimizing a worst-case perturbed loss over a small neighborhood of model parameters. However, during training, its optimization behavior does not always align with theoretical expectations, since both sharp and flat regions may yield a small perturbed loss. In such cases, the gradient may still point toward sharp regions, failing to achieve the intended effect of SAM. To address this issue, we investigate SAM from a spectral and geometric perspective: specifically, we utilize the angle between the gradient and the leading eigenvector of the Hessian as a measure of sharpness. Our analysis illustrates that when this angle is less than or equal to ninety degrees, the effect of SAM's sharpness regularization can be weakened. Furthermore, we propose an explicit eigenvector-aligned SAM (X-SAM), which corrects the gradient via orthogonal decomposition along the top eigenvector, enabling more direct and efficient regularization of the Hessian's maximum eigenvalue. We prove X-SAM's convergence and superior generalization, with extensive experimental evaluations confirming both theoretical and practical advantages.
Breaking Secure Aggregation: Label Leakage from Aggregated Gradients in Federated Learning
Jun 22, 2024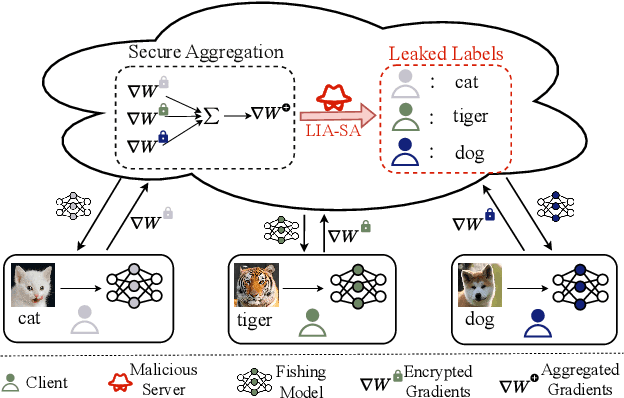
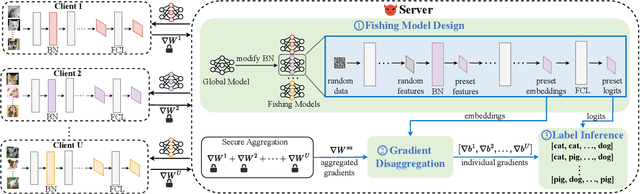
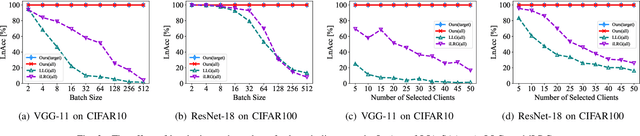
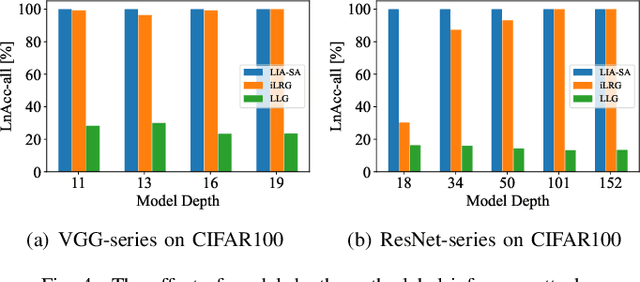
Federated Learning (FL) exhibits privacy vulnerabilities under gradient inversion attacks (GIAs), which can extract private information from individual gradients. To enhance privacy, FL incorporates Secure Aggregation (SA) to prevent the server from obtaining individual gradients, thus effectively resisting GIAs. In this paper, we propose a stealthy label inference attack to bypass SA and recover individual clients' private labels. Specifically, we conduct a theoretical analysis of label inference from the aggregated gradients that are exclusively obtained after implementing SA. The analysis results reveal that the inputs (embeddings) and outputs (logits) of the final fully connected layer (FCL) contribute to gradient disaggregation and label restoration. To preset the embeddings and logits of FCL, we craft a fishing model by solely modifying the parameters of a single batch normalization (BN) layer in the original model. Distributing client-specific fishing models, the server can derive the individual gradients regarding the bias of FCL by resolving a linear system with expected embeddings and the aggregated gradients as coefficients. Then the labels of each client can be precisely computed based on preset logits and gradients of FCL's bias. Extensive experiments show that our attack achieves large-scale label recovery with 100\% accuracy on various datasets and model architectures.