 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Surrogate Modeling for Personalized Blood Flow Prediction and Hemodynamic Analysis
Apr 03, 2026Cardiovascular modeling has rapidly advanced over the past few decades due to the rising needs for health tracking and early detection of cardiovascular diseases. While 1-D arterial models offer an attractive compromise between computational efficiency and solution fidelity, their application on large populations or for generating large \emph{in silico} cohorts remains challenging. Certain hemodynamic parameters like the terminal resistance/compliance, are difficult to clinically estimate and often yield non-physiological hemodynamics when sampled naively, resulting in large portions of simulated datasets to be discarded. In this work, we present a systematic framework for training machine learning (ML) models, capable of instantaneous hemodynamic prediction and parameter estimation. We initially start with generating a parametric virtual cohort of patients which is based on the multivariate correlations observed in the large Asklepios clinical dataset, ensuring that physiological parameter distributions are respected. We then train a deep neural surrogate model, able to predict patient-specific arterial pressure and cardiac output (CO), enabling rapid a~priori screening of input parameters. This allows for immediate rejection of non-physiological combinations and drastically reduces the cost of targeted synthetic dataset generation (e.g. hypertensive groups). The model also provides a principled means of sampling the terminal resistance to minimize the uncertainties of unmeasurable parameters. Moreover, by assessing the model's predictive performance we determine the theoretical information which suffices for solving the inverse problem of estimating the CO. Finally, we apply the surrogate on a clinical dataset for the estimation of central aortic hemodynamics i.e. the CO and aortic systolic blood pressure (cSBP).
Learning in PINNs: Phase transition, total diffusion, and generalization
Mar 27, 2024



We investigate the learning dynamics of fully-connected neural networks through the lens of gradient signal-to-noise ratio (SNR), examining the behavior of first-order optimizers like Adam in non-convex objectives. By interpreting the drift/diffusion phases in the information bottleneck theory, focusing on gradient homogeneity, we identify a third phase termed ``total diffusion", characterized by equilibrium in the learning rates and homogeneous gradients. This phase is marked by an abrupt SNR increase, uniform residuals across the sample space and the most rapid training convergence. We propose a residual-based re-weighting scheme to accelerate this diffusion in quadratic loss functions, enhancing generalization. We also explore the information compression phenomenon, pinpointing a significant saturation-induced compression of activations at the total diffusion phase, with deeper layers experiencing negligible information loss. Supported by experimental data on physics-informed neural networks (PINNs), which underscore the importance of gradient homogeneity due to their PDE-based sample inter-dependence, our findings suggest that recognizing phase transitions could refine ML optimization strategies for improved generalization.
Residual-based attention and connection to information bottleneck theory in PINNs
Jul 01, 2023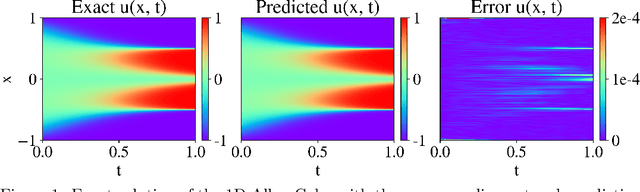
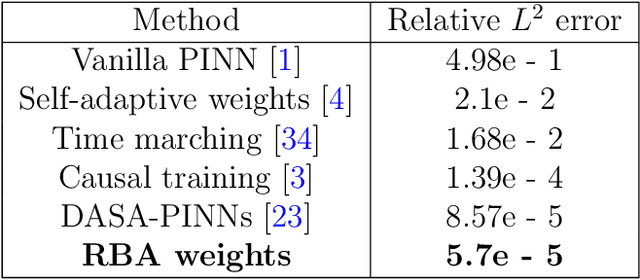
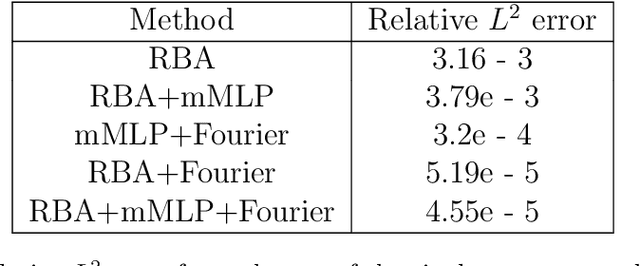
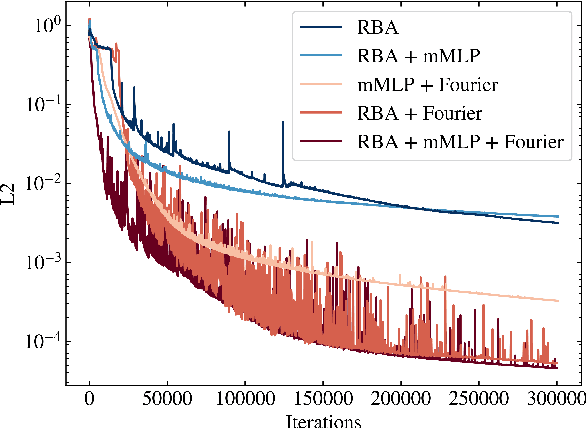
Driven by the need for more efficient and seamless integration of physical models and data, physics-informed neural networks (PINNs) have seen a surge of interest in recent years. However, ensuring the reliability of their convergence and accuracy remains a challenge. In this work, we propose an efficient, gradient-less weighting scheme for PINNs, that accelerates the convergence of dynamic or static systems. This simple yet effective attention mechanism is a function of the evolving cumulative residuals and aims to make the optimizer aware of problematic regions at no extra computational cost or adversarial learning. We illustrate that this general method consistently achieves a relative $L^{2}$ error of the order of $10^{-5}$ using standard optimizers on typical benchmark cases of the literature. Furthermore, by investigating the evolution of weights during training, we identify two distinct learning phases reminiscent of the fitting and diffusion phases proposed by the information bottleneck (IB) theory. Subsequent gradient analysis supports this hypothesis by aligning the transition from high to low signal-to-noise ratio (SNR) with the transition from fitting to diffusion regimes of the adopted weights. This novel correlation between PINNs and IB theory could open future possibilities for understanding the underlying mechanisms behind the training and stability of PINNs and, more broadly, of neural operators.