 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual-based attention and connection to information bottleneck theory in PINNs
Paper and Code
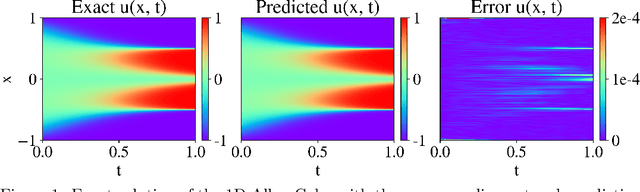
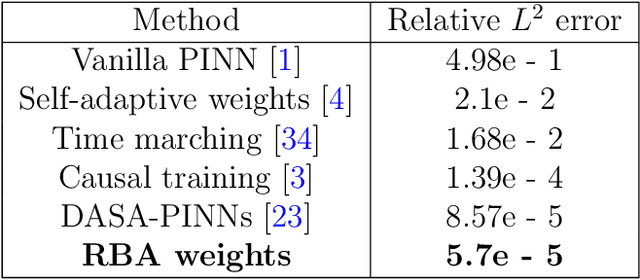
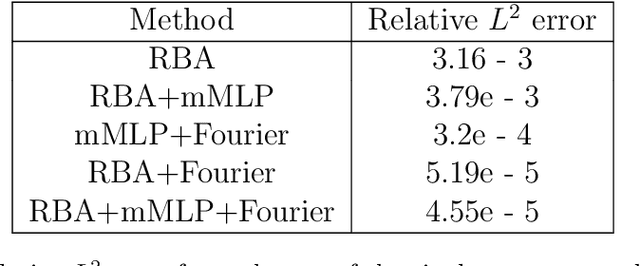
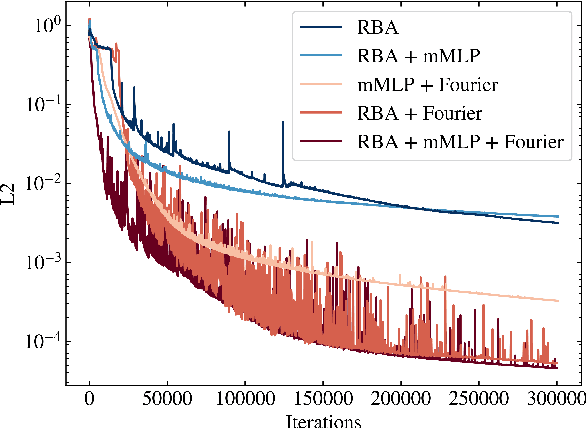
Driven by the need for more efficient and seamless integration of physical models and data, physics-informed neural networks (PINNs) have seen a surge of interest in recent years. However, ensuring the reliability of their convergence and accuracy remains a challenge. In this work, we propose an efficient, gradient-less weighting scheme for PINNs, that accelerates the convergence of dynamic or static systems. This simple yet effective attention mechanism is a function of the evolving cumulative residuals and aims to make the optimizer aware of problematic regions at no extra computational cost or adversarial learning. We illustrate that this general method consistently achieves a relative $L^{2}$ error of the order of $10^{-5}$ using standard optimizers on typical benchmark cases of the literature. Furthermore, by investigating the evolution of weights during training, we identify two distinct learning phases reminiscent of the fitting and diffusion phases proposed by the information bottleneck (IB) theory. Subsequent gradient analysis supports this hypothesis by aligning the transition from high to low signal-to-noise ratio (SNR) with the transition from fitting to diffusion regimes of the adopted weights. This novel correlation between PINNs and IB theory could open future possibilities for understanding the underlying mechanisms behind the training and stability of PINNs and, more broadly, of neural operators.