 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Latency Transformer Inference on FPGAs for Physics Applications with hls4ml
Sep 08, 2024



This study presents an efficient implementation of transformer architectures in Field-Programmable Gate Arrays(FPGAs) using hls4ml. We demonstrate the strategy for implementing the multi-head attention, softmax, and normalization layer and evaluate three distinct models. Their deployment on VU13P FPGA chip achieved latency less than 2us, demonstrating the potential for real-time applications. HLS4ML compatibility with any TensorFlow-built transformer model further enhances the scalability and applicability of this work. Index Terms: FPGAs, machine learning, transformers, high energy physics, LIGO
Ultra Fast Transformers on FPGAs for Particle Physics Experiments
Feb 01, 2024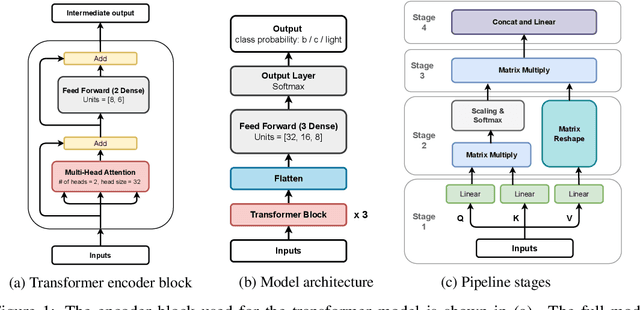
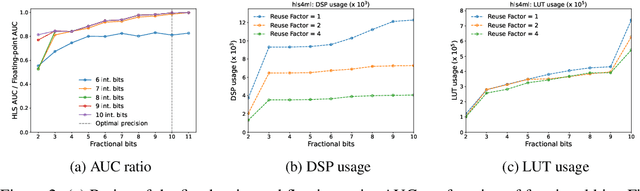
This work introduces a highly efficient implementation of the transformer architecture on a Field-Programmable Gate Array (FPGA) by using the \texttt{hls4ml} tool. Given the demonstrated effectiveness of transformer models in addressing a wide range of problems, their application in experimental triggers within particle physics becomes a subject of significant interest. In this work, we have implemented critical components of a transformer model, such as multi-head attention and softmax layers. To evaluate the effectiveness of our implementation, we have focused on a particle physics jet flavor tagging problem, employing a public dataset. We recorded latency under 2 $\mu$s on the Xilinx UltraScale+ FPGA, which is compatible with hardware trigger requirements at the CERN Large Hadron Collider experiments.
* 6 pages, 2 figures