 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWARP Logic Neural Networks
Feb 03, 2026Fast and efficient AI inference is increasingly important, and recent models that directly learn low-level logic operations have achieved state-of-the-art performance. However, existing logic neural networks incur high training costs, introduce redundancy or rely on approximate gradients, which limits scalability. To overcome these limitations, we introduce WAlsh Relaxation for Probabilistic (WARP) logic neural networks -- a novel gradient-based framework that efficiently learns combinations of hardware-native logic blocks. We show that WARP yields the most parameter-efficient representation for exactly learning Boolean functions and that several prior approaches arise as restricted special cases. Training is improved by introducing learnable thresholding and residual initialization, while we bridge the gap between relaxed training and discrete logic inference through stochastic smoothing. Experiments demonstrate faster convergence than state-of-the-art baselines, while scaling effectively to deeper architectures and logic functions with higher input arity.
Knowledge Distillation for Anomaly Detection
Oct 09, 2023


Unsupervised deep learning techniques are widely used to identify anomalous behaviour. The performance of such methods is a product of the amount of training data and the model size. However, the size is often a limiting factor for the deployment on resource-constrained devices. We present a novel procedure based on knowledge distillation for compressing an unsupervised anomaly detection model into a supervised deployable one and we suggest a set of techniques to improve the detection sensitivity. Compressed models perform comparably to their larger counterparts while significantly reducing the size and memory footprint.
Symbolic Regression on FPGAs for Fast Machine Learning Inference
May 06, 2023



The high-energy physics community is investigating the feasibility of deploying machine-learning-based solutions on Field-Programmable Gate Arrays (FPGAs) to improve physics sensitivity while meeting data processing latency limitations. In this contribution, we introduce a novel end-to-end procedure that utilizes a machine learning technique called symbolic regression (SR). It searches equation space to discover algebraic relations approximating a dataset. We use PySR (software for uncovering these expressions based on evolutionary algorithm) and extend the functionality of hls4ml (a package for machine learning inference in FPGAs) to support PySR-generated expressions for resource-constrained production environments. Deep learning models often optimise the top metric by pinning the network size because vast hyperparameter space prevents extensive neural architecture search. Conversely, SR selects a set of models on the Pareto front, which allows for optimising the performance-resource tradeoff directly. By embedding symbolic forms, our implementation can dramatically reduce the computational resources needed to perform critical tasks. We validate our procedure on a physics benchmark: multiclass classification of jets produced in simulated proton-proton collisions at the CERN Large Hadron Collider, and show that we approximate a 3-layer neural network with an inference model that has as low as 5 ns execution time (a reduction by a factor of 13) and over 90% approximation accuracy.
Graph Neural Networks for Charged Particle Tracking on FPGAs
Dec 03, 2021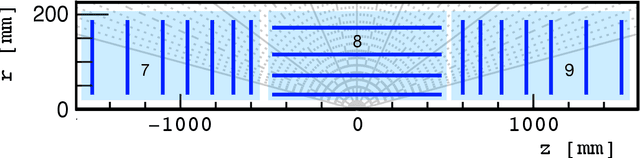

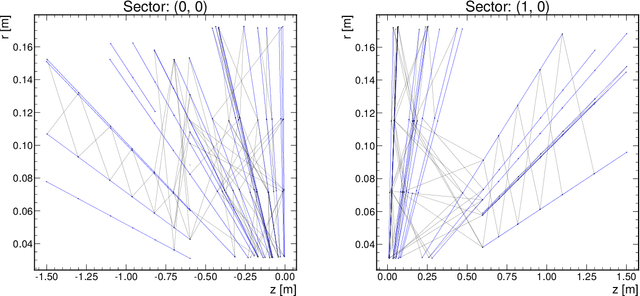
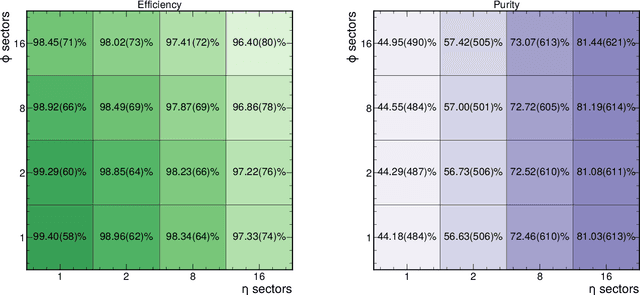
The determination of charged particle trajectories in collisions at the CERN Large Hadron Collider (LHC) is an important but challenging problem, especially in the high interaction density conditions expected during the future high-luminosity phase of the LHC (HL-LHC). Graph neural networks (GNNs) are a type of geometric deep learning algorithm that has successfully been applied to this task by embedding tracker data as a graph -- nodes represent hits, while edges represent possible track segments -- and classifying the edges as true or fake track segments. However, their study in hardware- or software-based trigger applications has been limited due to their large computational cost. In this paper, we introduce an automated translation workflow, integrated into a broader tool called $\texttt{hls4ml}$, for converting GNNs into firmware for field-programmable gate arrays (FPGAs). We use this translation tool to implement GNNs for charged particle tracking, trained using the TrackML challenge dataset, on FPGAs with designs targeting different graph sizes, task complexites, and latency/throughput requirements. This work could enable the inclusion of charged particle tracking GNNs at the trigger level for HL-LHC experiments.
Charged particle tracking via edge-classifying interaction networks
Mar 30, 2021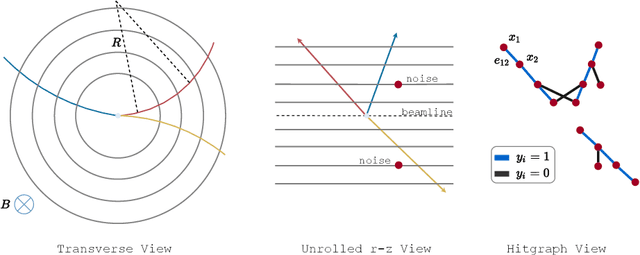
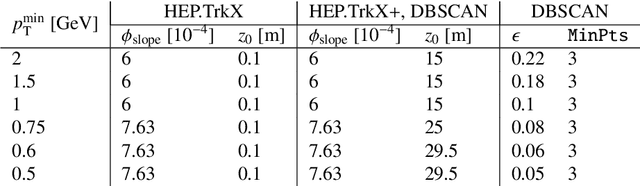
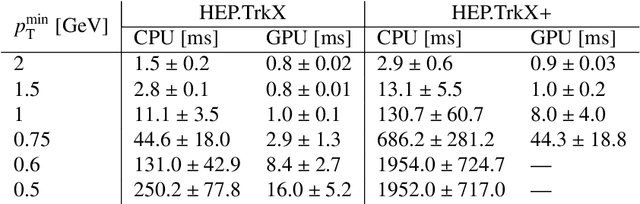
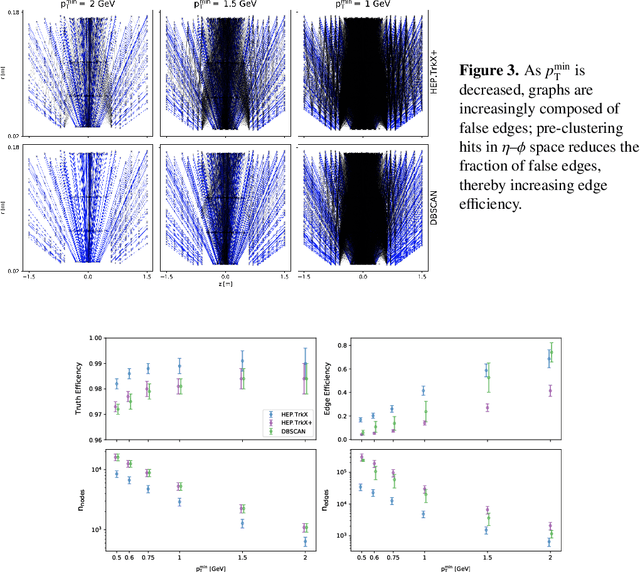
Recent work has demonstrated that geometric deep learning methods such as graph neural networks (GNNs) are well-suited to address a variety of reconstruction problems in HEP. In particular, tracker events are naturally represented as graphs by identifying hits as nodes and track segments as edges; given a set of hypothesized edges, edge-classifying GNNs predict which correspond to real track segments. In this work, we adapt the physics-motivated interaction network (IN) GNN to the problem of charged-particle tracking in the high-pileup conditions expected at the HL-LHC. We demonstrate the IN's excellent edge-classification accuracy and tracking efficiency through a suite of measurements at each stage of GNN-based tracking: graph construction, edge classification, and track building. The proposed IN architecture is substantially smaller than previously studied GNN tracking architectures, a reduction in size critical for enabling GNN-based tracking in constrained computing environments. Furthermore, the IN is easily expressed as a set of matrix operations, making it a promising candidate for acceleration via heterogeneous computing resources.
Accelerated Charged Particle Tracking with Graph Neural Networks on FPGAs
Nov 30, 2020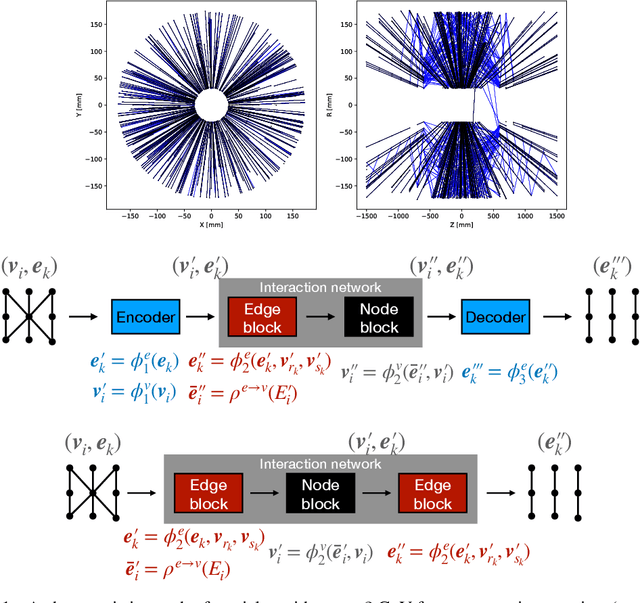
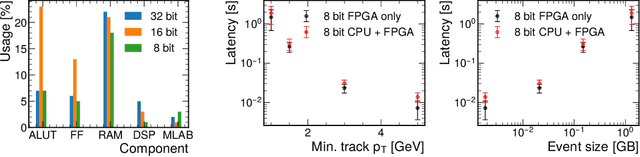


We develop and study FPGA implementations of algorithms for charged particle tracking based on graph neural networks. The two complementary FPGA designs are based on OpenCL, a framework for writing programs that execute across heterogeneous platforms, and hls4ml, a high-level-synthesis-based compiler for neural network to firmware conversion. We evaluate and compare the resource usage, latency, and tracking performance of our implementations based on a benchmark dataset. We find a considerable speedup over CPU-based execution is possible, potentially enabling such algorithms to be used effectively in future computing workflows and the FPGA-based Level-1 trigger at the CERN Large Hadron Collider.