 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGPR: Tree-Guided Policy Refinement for Robust Self-Debugging of LLMs
Oct 08, 2025



Iterative refinement has been a promising paradigm to enable large language models (LLMs) to resolve difficult reasoning and problem-solving tasks. One of the key challenges, however, is how to effectively search through the enormous search space of possible refinements. Existing methods typically fall back on predefined heuristics, which are troubled by the exploration-exploitation dilemma and cannot adapt based on past refinement outcomes. We introduce Tree-Guided Policy Refinement (TGPR), a novel framework that combines GRPO with a Thompson-Sampling-based tree search. TGPR explores both failed and successful refinement paths actively, with denser training trajectories and more adaptive policies. On HumanEval, MBPP, and APPS benchmarks, our method achieves up to +4.2 percentage points absolute improvement in pass@1 (on MBPP) and up to +12.51 percentage points absolute improvement in pass@10 (on APPS) compared to a competitive GRPO baseline. Apart from debugging code, TGPR focuses on a principled approach to combining learned policies with structured search methods, offering a general framework for enhancing iterative refinement and stateful reasoning in LLMs.
CodeRefine: A Pipeline for Enhancing LLM-Generated Code Implementations of Research Papers
Aug 23, 2024



This paper presents CodeRefine, a novel framework for automatically transforming research paper methodologies into functional code using Large Language Models (LLMs). Our multi-step approach first extracts and summarizes key text chunks from papers, analyzes their code relevance, and creates a knowledge graph using a predefined ontology. Code is then generated from this structured representation and enhanced through a proposed retrospective retrieval-augmented generation approach. CodeRefine addresses the challenge of bridging theoretical research and practical implementation, offering a more accurate alternative to LLM zero-shot prompting. Evaluations on diverse scientific papers demonstrate CodeRefine's ability to improve code implementation from the paper, potentially accelerating the adoption of cutting-edge algorithms in real-world applications.
Linguacodus: A Synergistic Framework for Transformative Code Generation in Machine Learning Pipelines
Mar 18, 2024In the ever-evolving landscape of machine learning, seamless translation of natural language descriptions into executable code remains a formidable challenge. This paper introduces Linguacodus, an innovative framework designed to tackle this challenge by deploying a dynamic pipeline that iteratively transforms natural language task descriptions into code through high-level data-shaping instructions. The core of Linguacodus is a fine-tuned large language model (LLM), empowered to evaluate diverse solutions for various problems and select the most fitting one for a given task. This paper details the fine-tuning process, and sheds light on how natural language descriptions can be translated into functional code. Linguacodus represents a substantial leap towards automated code generation, effectively bridging the gap between task descriptions and executable code. It holds great promise for advancing machine learning applications across diverse domains. Additionally, we propose an algorithm capable of transforming a natural description of an ML task into code with minimal human interaction. In extensive experiments on a vast machine learning code dataset originating from Kaggle, we showcase the effectiveness of Linguacodus. The investigations highlight its potential applications across diverse domains, emphasizing its impact on applied machine learning in various scientific fields.
Segmentation of EM showers for neutrino experiments with deep graph neural networks
Apr 16, 2021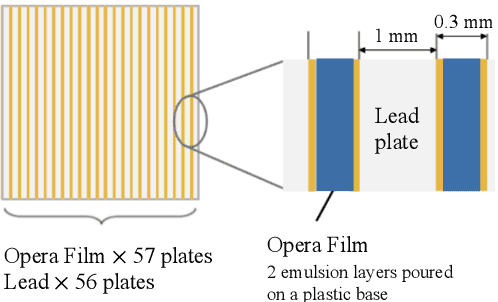
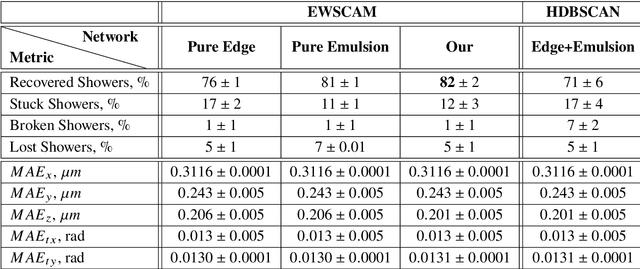
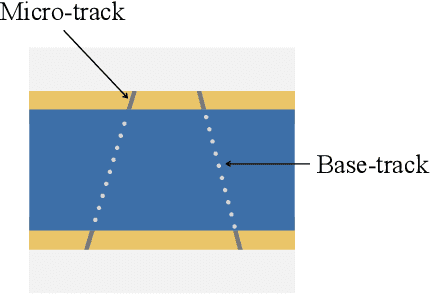
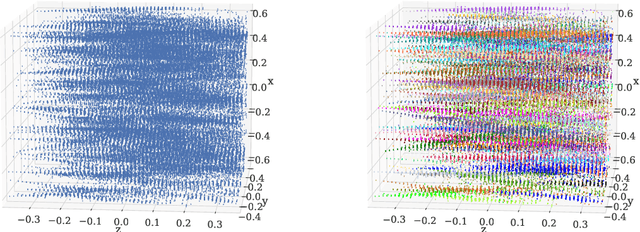
We introduce a novel method for showers reconstruction from the data collected with electromagnetic (EM) sampling calorimeters. Such detectors are widely used in High Energy Physics to measure the energy and kinematics of in-going particles. In this work, we consider the case when a large number of particles pass through an Emulsion Cloud Chamber (ECC) brick, generating electromagnetic showers. This situation can be observed with long exposure times or large input particle flux. For example, SHiP experiment is planning to use emulsion detectors for dark matter search and neutrino physics investigation. The expected full flux of SHiP experiment is about $10^{20}$ particles over five years. Because of the high amount of in-going particles, we will observe a lot of overlapping showers. It makes EM showers reconstruction a challenging segmentation problem. Our reconstruction pipeline consists of a Graph Neural Network that predicts an adjacency matrix for the clustering algorithm. To improve Graph Neural Network's performance, we propose a new layer type (EmulsionConv) that takes into account geometrical properties of shower development in ECC brick. For the clustering of overlapping showers, we use a modified hierarchical density-based clustering algorithm. Our method does not use any prior information about the incoming particles and identifies up to 82% of electromagnetic showers in emulsion detectors. The mean energy resolution over $17,715$ showers is 27%. The main test bench for the algorithm for reconstructing electromagnetic showers is going to be SND@LHC.