 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of FPGA and GPU Performance for Machine Learning-Based Track Reconstruction at LHCb
Feb 05, 2025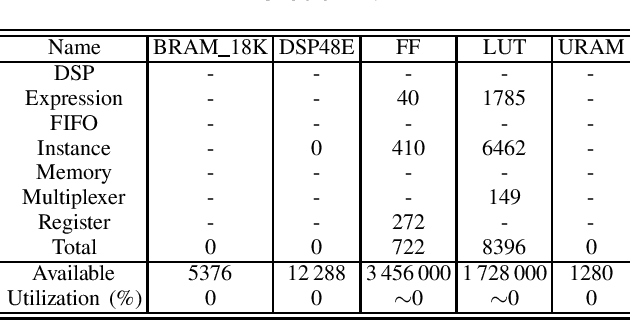
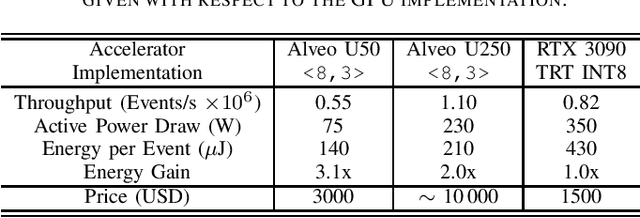
In high-energy physics, the increasing luminosity and detector granularity at the Large Hadron Collider are driving the need for more efficient data processing solutions. Machine Learning has emerged as a promising tool for reconstructing charged particle tracks, due to its potentially linear computational scaling with detector hits. The recent implementation of a graph neural network-based track reconstruction pipeline in the first level trigger of the LHCb experiment on GPUs serves as a platform for comparative studies between computational architectures in the context of high-energy physics. This paper presents a novel comparison of the throughput of ML model inference between FPGAs and GPUs, focusing on the first step of the track reconstruction pipeline$\unicode{x2013}$an implementation of a multilayer perceptron. Using HLS4ML for FPGA deployment, we benchmark its performance against the GPU implementation and demonstrate the potential of FPGAs for high-throughput, low-latency inference without the need for an expertise in FPGA development and while consuming significantly less power.
The Tracking Machine Learning challenge : Throughput phase
May 14, 2021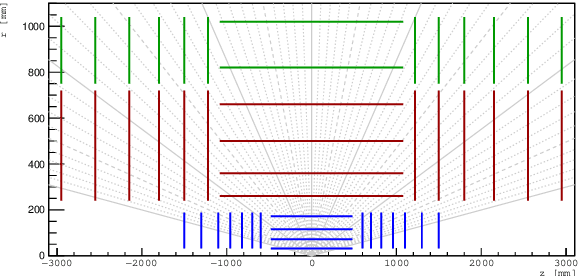
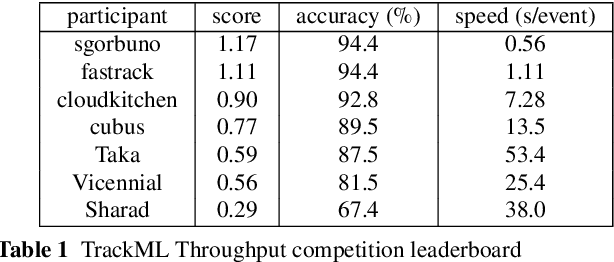
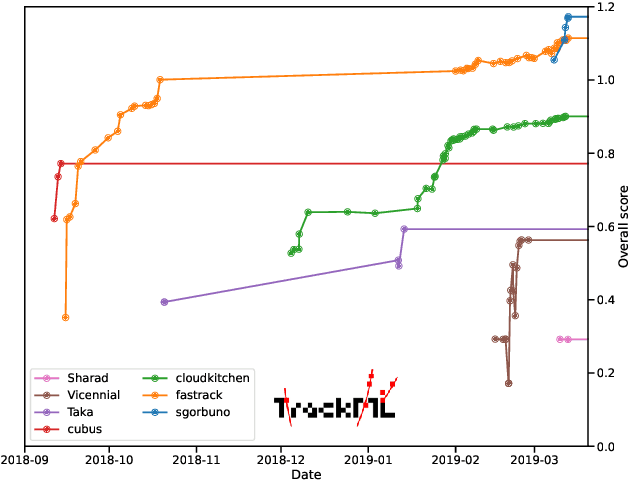
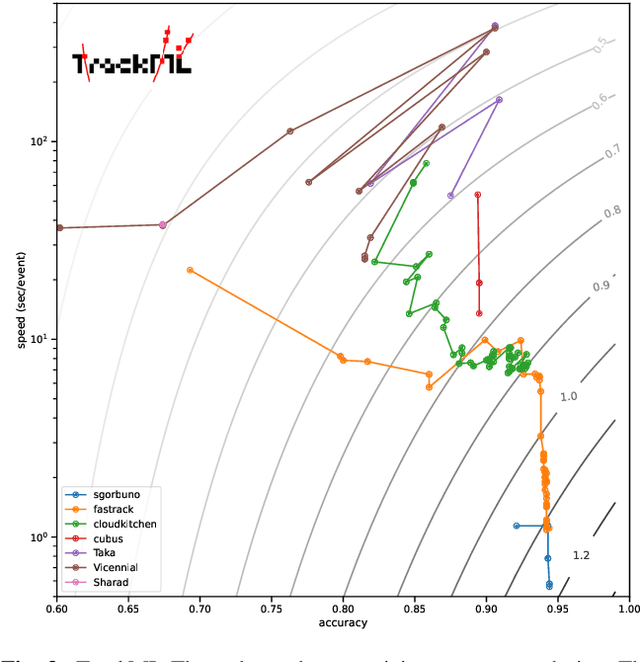
This paper reports on the second "Throughput" phase of the Tracking Machine Learning (TrackML) challenge on the Codalab platform. As in the first "Accuracy" phase, the participants had to solve a difficult experimental problem linked to tracking accurately the trajectory of particles as e.g. created at the Large Hadron Collider (LHC): given O($10^5$) points, the participants had to connect them into O($10^4$) individual groups that represent the particle trajectories which are approximated helical. While in the first phase only the accuracy mattered, the goal of this second phase was a compromise between the accuracy and the speed of inference. Both were measured on the Codalab platform where the participants had to upload their software. The best three participants had solutions with good accuracy and speed an order of magnitude faster than the state of the art when the challenge was designed. Although the core algorithms were less diverse than in the first phase, a diversity of techniques have been used and are described in this paper. The performance of the algorithms are analysed in depth and lessons derived.