 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline detection of failures generated by storage simulator
Paper and Code
Jan 18, 2021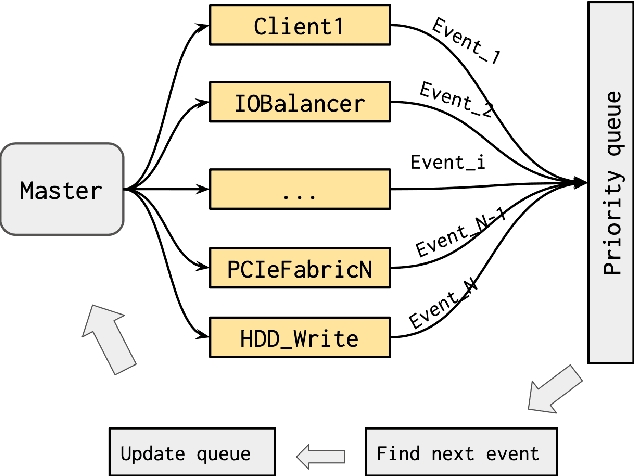

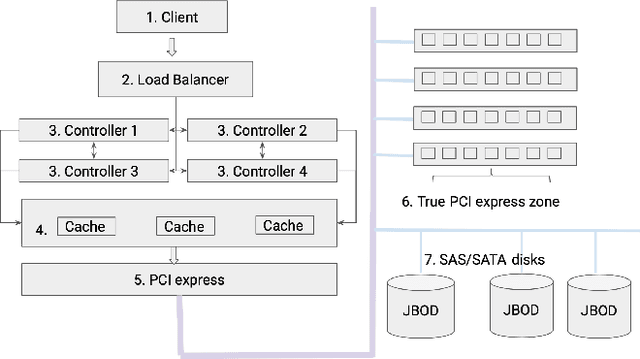
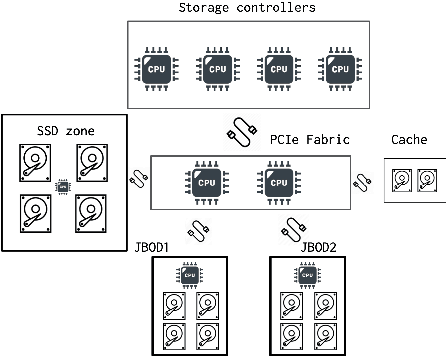
Modern large-scale data-farms consist of hundreds of thousands of storage devices that span distributed infrastructure. Devices used in modern data centers (such as controllers, links, SSD- and HDD-disks) can fail due to hardware as well as software problems. Such failures or anomalies can be detected by monitoring the activity of components using machine learning techniques. In order to use these techniques, researchers need plenty of historical data of devices in normal and failure mode for training algorithms. In this work, we challenge two problems: 1) lack of storage data in the methods above by creating a simulator and 2) applying existing online algorithms that can faster detect a failure occurred in one of the components. We created a Go-based (golang) package for simulating the behavior of modern storage infrastructure. The software is based on the discrete-event modeling paradigm and captures the structure and dynamics of high-level storage system building blocks. The package's flexible structure allows us to create a model of a real-world storage system with a configurable number of components. The primary area of interest is exploring the storage machine's behavior under stress testing or exploitation in the medium- or long-term for observing failures of its components. To discover failures in the time series distribution generated by the simulator, we modified a change point detection algorithm that works in online mode. The goal of the change-point detection is to discover differences in time series distribution. This work describes an approach for failure detection in time series data based on direct density ratio estimation via binary classifiers.