 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Artificial Modalities to Solve RGB Liveness
Jun 29, 2020



Special cameras that provide useful features for face anti-spoofing are desirable, but not always an option. In this work we propose a method to utilize the difference in dynamic appearance between bona fide and spoof samples by creating artificial modalities from RGB videos. We introduce two types of artificial transforms: rank pooling and optical flow, combined in end-to-end pipeline for spoof detection. We demonstrate that using intermediate representations that contain less identity and fine-grained features increase model robustness to unseen attacks as well as to unseen ethnicities. The proposed method achieves state-of-the-art on the largest cross-ethnicity face anti-spoofing dataset CASIA-SURF CeFA (RGB).
Learnable Visual Markers
Oct 28, 2016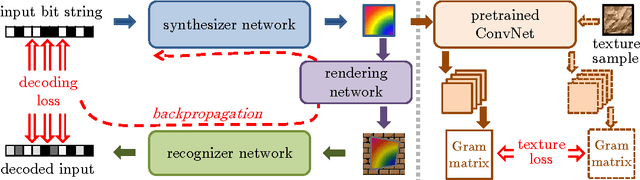

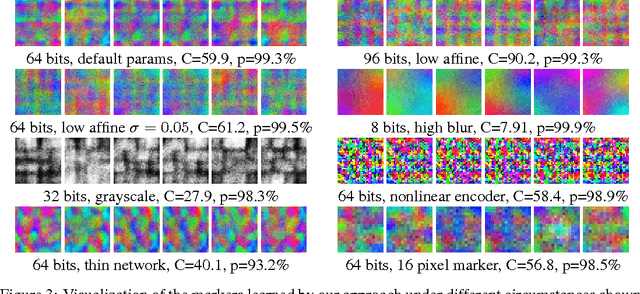
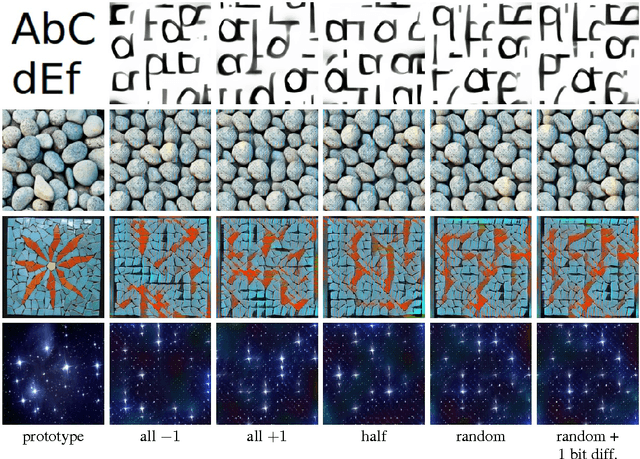
We propose a new approach to designing visual markers (analogous to QR-codes, markers for augmented reality, and robotic fiducial tags) based on the advances in deep generative networks. In our approach, the markers are obtained as color images synthesized by a deep network from input bit strings, whereas another deep network is trained to recover the bit strings back from the photos of these markers. The two networks are trained simultaneously in a joint backpropagation process that takes characteristic photometric and geometric distortions associated with marker fabrication and marker scanning into account. Additionally, a stylization loss based on statistics of activations in a pretrained classification network can be inserted into the learning in order to shift the marker appearance towards some texture prototype. In the experiments, we demonstrate that the markers obtained using our approach are capable of retaining bit strings that are long enough to be practical. The ability to automatically adapt markers according to the usage scenario and the desired capacity as well as the ability to combine information encoding with artistic stylization are the unique properties of our approach. As a byproduct, our approach provides an insight on the structure of patterns that are most suitable for recognition by ConvNets and on their ability to distinguish composite patterns.