 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Scientific Learning Beyond Diffusions and Flows
Feb 01, 2026Scientific machine learning (SciML) increasingly requires models that capture multimodal conditional uncertainty arising from ill-posed inverse problems, multistability, and chaotic dynamics. While recent work has favored highly expressive implicit generative models such as diffusion and flow-based methods, these approaches are often data-hungry, computationally costly, and misaligned with the structured solution spaces frequently found in scientific problems. We demonstrate that Mixture Density Networks (MDNs) provide a principled yet largely overlooked alternative for multimodal uncertainty quantification in SciML. As explicit parametric density estimators, MDNs impose an inductive bias tailored to low-dimensional, multimodal physics, enabling direct global allocation of probability mass across distinct solution branches. This structure delivers strong data efficiency, allowing reliable recovery of separated modes in regimes where scientific data is scarce. We formalize these insights through a unified probabilistic framework contrasting explicit and implicit distribution networks, and demonstrate empirically that MDNs achieve superior generalization, interpretability, and sample efficiency across a range of inverse, multistable, and chaotic scientific regression tasks.
Active Learning Design: Modeling Force Output for Axisymmetric Soft Pneumatic Actuators
Apr 01, 2025Soft pneumatic actuators (SPA) made from elastomeric materials can provide large strain and large force. The behavior of locally strain-restricted hyperelastic materials under inflation has been investigated thoroughly for shape reconfiguration, but requires further investigation for trajectories involving external force. In this work we model force-pressure-height relationships for a concentrically strain-limited class of soft pneumatic actuators and demonstrate the use of this model to design SPA response for object lifting. We predict relationships under different loadings by solving energy minimization equations and verify this theory by using an automated test rig to collect rich data for n=22 Ecoflex 00-30 membranes. We collect this data using an active learning pipeline to efficiently model the design space. We show that this learned material model outperforms the theory-based model and naive curve-fitting approaches. We use our model to optimize membrane design for different lift tasks and compare this performance to other designs. These contributions represent a step towards understanding the natural response for this class of actuator and embodying intelligent lifts in a single-pressure input actuator system.
Deep Learning Alternatives of the Kolmogorov Superposition Theorem
Oct 02, 2024
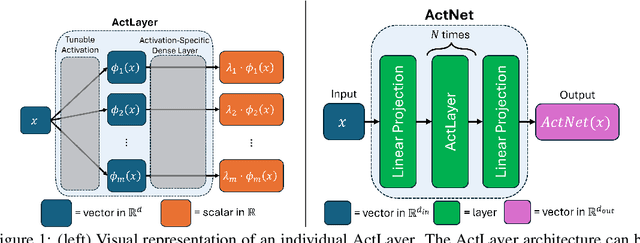
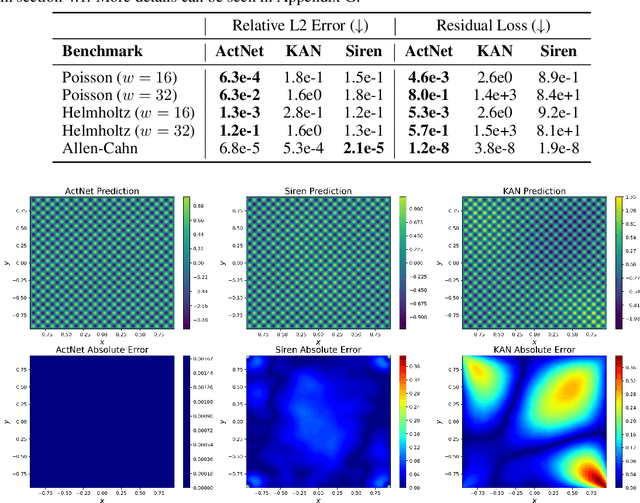
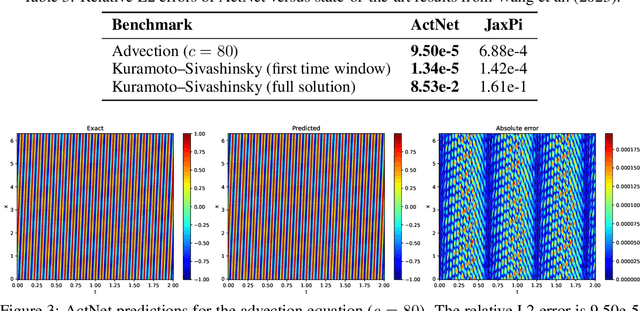
This paper explores alternative formulations of the Kolmogorov Superposition Theorem (KST) as a foundation for neural network design. The original KST formulation, while mathematically elegant, presents practical challenges due to its limited insight into the structure of inner and outer functions and the large number of unknown variables it introduces. Kolmogorov-Arnold Networks (KANs) leverage KST for function approximation, but they have faced scrutiny due to mixed results compared to traditional multilayer perceptrons (MLPs) and practical limitations imposed by the original KST formulation. To address these issues, we introduce ActNet, a scalable deep learning model that builds on the KST and overcomes many of the drawbacks of Kolmogorov's original formulation. We evaluate ActNet in the context of Physics-Informed Neural Networks (PINNs), a framework well-suited for leveraging KST's strengths in low-dimensional function approximation, particularly for simulating partial differential equations (PDEs). In this challenging setting, where models must learn latent functions without direct measurements, ActNet consistently outperforms KANs across multiple benchmarks and is competitive against the current best MLP-based approaches. These results present ActNet as a promising new direction for KST-based deep learning applications, particularly in scientific computing and PDE simulation tasks.
Composite Bayesian Optimization In Function Spaces Using NEON -- Neural Epistemic Operator Networks
Apr 03, 2024Operator learning is a rising field of scientific computing where inputs or outputs of a machine learning model are functions defined in infinite-dimensional spaces. In this paper, we introduce NEON (Neural Epistemic Operator Networks), an architecture for generating predictions with uncertainty using a single operator network backbone, which presents orders of magnitude less trainable parameters than deep ensembles of comparable performance. We showcase the utility of this method for sequential decision-making by examining the problem of composite Bayesian Optimization (BO), where we aim to optimize a function $f=g\circ h$, where $h:X\to C(\mathcal{Y},\mathbb{R}^{d_s})$ is an unknown map which outputs elements of a function space, and $g: C(\mathcal{Y},\mathbb{R}^{d_s})\to \mathbb{R}$ is a known and cheap-to-compute functional. By comparing our approach to other state-of-the-art methods on toy and real world scenarios, we demonstrate that NEON achieves state-of-the-art performance while requiring orders of magnitude less trainable parameters.
Learning Operators with Coupled Attention
Jan 04, 2022



Supervised operator learning is an emerging machine learning paradigm with applications to modeling the evolution of spatio-temporal dynamical systems and approximating general black-box relationships between functional data. We propose a novel operator learning method, LOCA (Learning Operators with Coupled Attention), motivated from the recent success of the attention mechanism. In our architecture, the input functions are mapped to a finite set of features which are then averaged with attention weights that depend on the output query locations. By coupling these attention weights together with an integral transform, LOCA is able to explicitly learn correlations in the target output functions, enabling us to approximate nonlinear operators even when the number of output function in the training set measurements is very small. Our formulation is accompanied by rigorous approximation theoretic guarantees on the universal expressiveness of the proposed model. Empirically, we evaluate the performance of LOCA on several operator learning scenarios involving systems governed by ordinary and partial differential equations, as well as a black-box climate prediction problem. Through these scenarios we demonstrate state of the art accuracy, robustness with respect to noisy input data, and a consistently small spread of errors over testing data sets, even for out-of-distribution prediction tasks.