 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Confusing: Region-Aware Network for Human Pose Estimation
Paper and Code
May 27, 2019
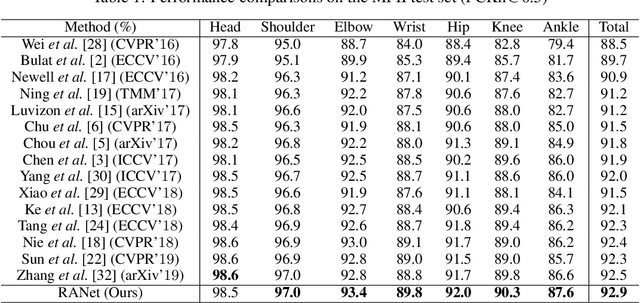
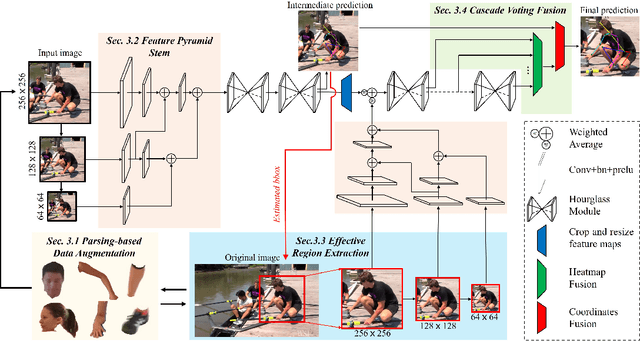
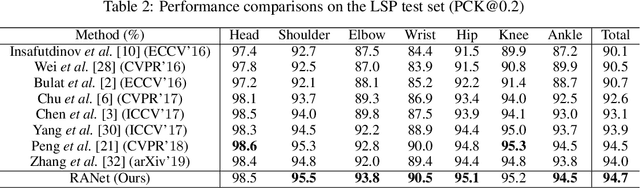
In this work, we propose a novel framework named Region-Aware Network (RANet), which learns the ability of anti-confusing in case of heavy occlusion, nearby person and symmetric appearance, for human pose estimation. Specifically, the proposed method addresses three key aspects, i.e., data augmentation, feature learning and prediction fusion, respectively. First, we propose Parsing-based Data Augmentation (PDA) to generate abundant data that synthesizes confusing textures. Second, we not only propose a Feature Pyramid Stem (FPS) to learn stronger low-level features in lower stage; but also incorporate an Effective Region Extraction (ERE) module to excavate better target-specific features. Third, we introduce Cascade Voting Fusion (CVF) to explicitly exclude the inferior predictions and fuse the rest effective predictions for the final pose estimation. Extensive experimental results on two popular benchmarks, i.e. MPII and LSP, demonstrate the effectiveness of our method against the state-of-the-art competitors. Especially on easily-confusable joints, our method makes significant improvement.