 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Rendering Framework for Free-Viewpoint Relighting
Nov 26, 2019

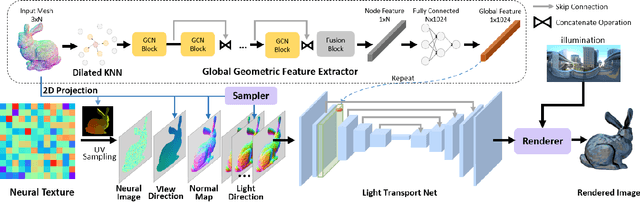
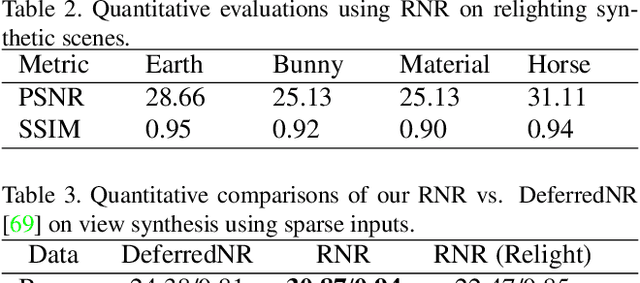
We present a novel Relightable Neural Renderer (RNR) for simultaneous view synthesis and relighting using multi-view image inputs. Existing neural rendering (NR) does not explicitly model the physical rendering process and hence has limited capabilities on relighting. RNR instead models image formation in terms of environment lighting, object intrinsic attributes, and the light transport function (LTF), each corresponding to a learnable component. In particular, the incorporation of a physically based rendering process not only enables relighting but also improves the quality of novel view synthesis. Comprehensive experiments on synthetic and real data show that RNR provides a practical and effective solution for conducting free-viewpoint relighting.
Photo-Realistic Facial Details Synthesis from Single Immage
Mar 26, 2019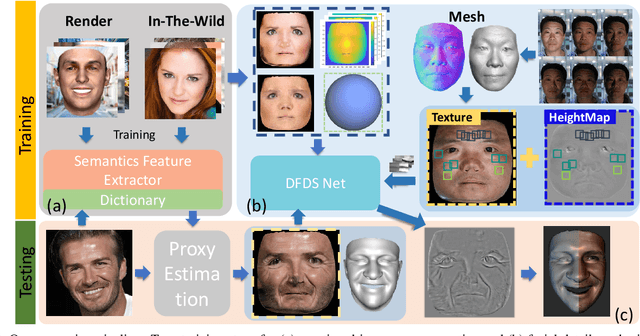
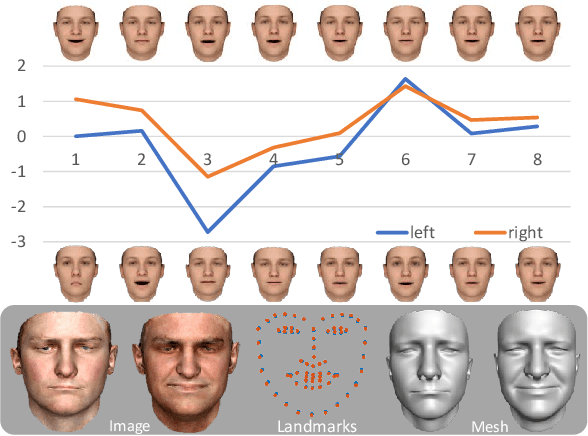

We present a single-image 3D face synthesis technique that can handle challenging facial expressions while recovering fine geometric details. Our technique employs expression analysis for proxy face geometry generation and combines supervised and unsupervised learning for facial detail synthesis. On proxy generation, we conduct emotion prediction to determine a new expression-informed proxy. On detail synthesis, we present a Deep Facial Detail Net (DFDN) based on Conditional Generative Adversarial Net (CGAN) that employs both geometry and appearance loss functions. For geometry, we capture 366 high-quality 3D scans from 122 different subjects under 3 facial expressions. For appearance, we use additional 20K in-the-wild face images and apply image-based rendering to accommodate lighting variations. Comprehensive experiments demonstrate that our framework can produce high-quality 3D faces with realistic details under challenging facial expressions.
Hair Segmentation on Time-of-Flight RGBD Images
Mar 11, 2019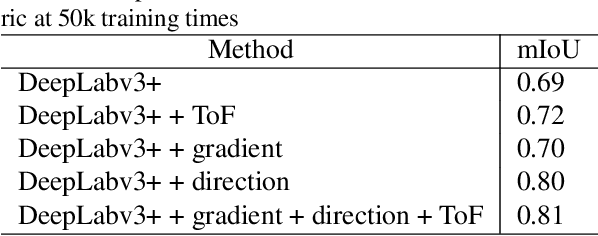
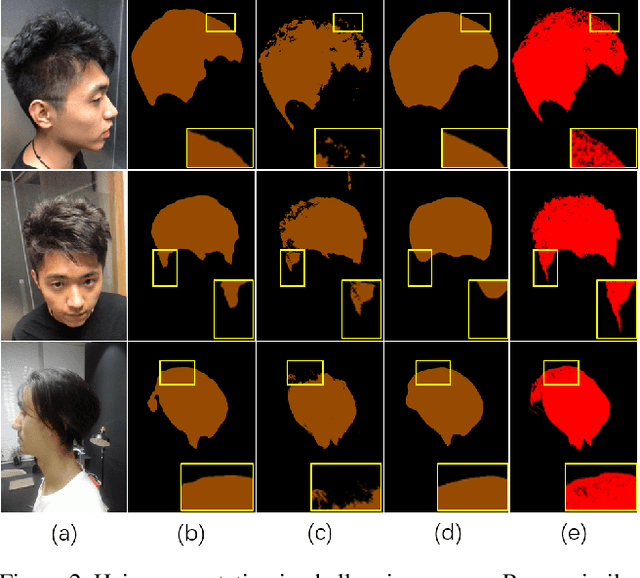
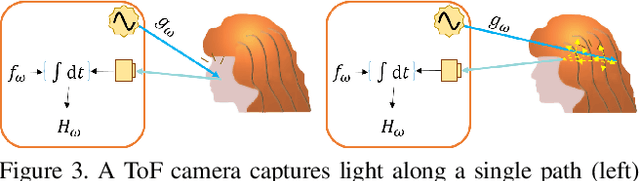
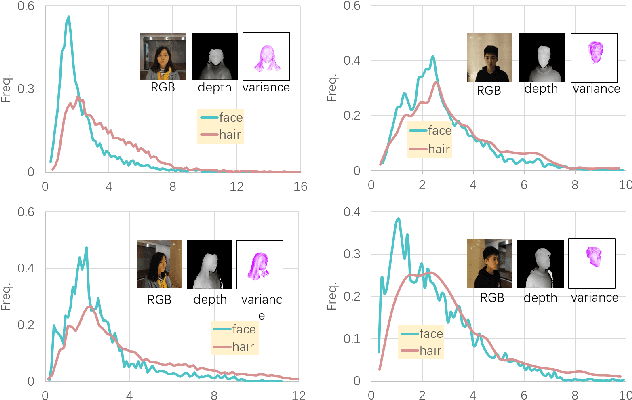
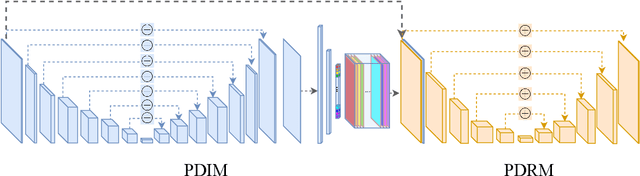
Robust segmentation of hair from portrait images remains challenging: hair does not conform to a uniform shape, style or even color; dark hair in particular lacks features. We present a novel computational imaging solution that tackles the problem from both input and processing fronts. We explore using Time-of-Flight (ToF) RGBD sensors on recent mobile devices. We first conduct a comprehensive analysis to show that scattering and inter-reflection cause different noise patterns on hair vs. non-hair regions on ToF images, by changing the light path and/or combining multiple paths. We then develop a deep network based approach that employs both ToF depth map and the RGB gradient maps to produce an initial hair segmentation with labeled hair components. We then refine the result by imposing ToF noise prior under the conditional random field. We collect the first ToF RGBD hair dataset with 20k+ head images captured on 30 human subjects with a variety of hairstyles at different view angles. Comprehensive experiments show that our approach outperforms the RGB based techniques in accuracy and robustness and can handle traditionally challenging cases such as dark hair, similar hair/background, similar hair/foreground, etc.
Semantic See-Through Rendering on Light Fields
Mar 26, 2018
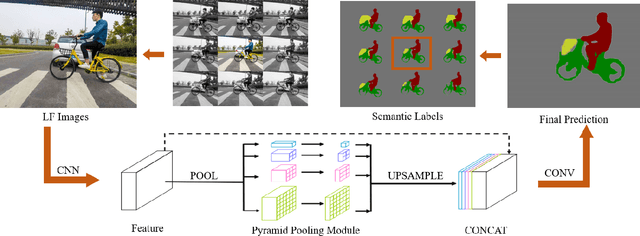

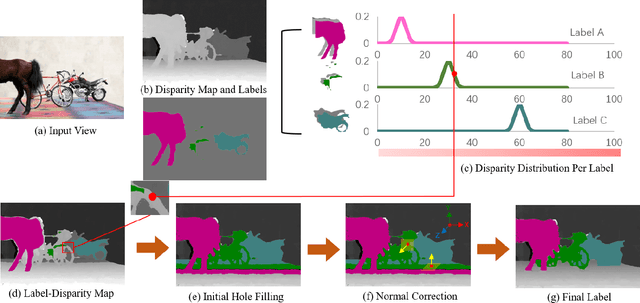
We present a novel semantic light field (LF) refocusing technique that can achieve unprecedented see-through quality. Different from prior art, our semantic see-through (SST) differentiates rays in their semantic meaning and depth. Specifically, we combine deep learning and stereo matching to provide each ray a semantic label. We then design tailored weighting schemes for blending the rays. Although simple, our solution can effectively remove foreground residues when focusing on the background. At the same time, SST maintains smooth transitions in varying focal depths. Comprehensive experiments on synthetic and new real indoor and outdoor datasets demonstrate the effectiveness and usefulness of our technique.