 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMienCap: Realtime Performance-Based Facial Animation with Live Mood Dynamics
Aug 06, 2025



Our purpose is to improve performance-based animation which can drive believable 3D stylized characters that are truly perceptual. By combining traditional blendshape animation techniques with multiple machine learning models, we present both non-real time and real time solutions which drive character expressions in a geometrically consistent and perceptually valid way. For the non-real time system, we propose a 3D emotion transfer network makes use of a 2D human image to generate a stylized 3D rig parameters. For the real time system, we propose a blendshape adaption network which generates the character rig parameter motions with geometric consistency and temporally stability. We demonstrate the effectiveness of our system by comparing to a commercial product Faceware. Results reveal that ratings of the recognition, intensity, and attractiveness of expressions depicted for animated characters via our systems are statistically higher than Faceware. Our results may be implemented into the animation pipeline, and provide animators with a system for creating the expressions they wish to use more quickly and accurately.
Photo-Realistic Facial Details Synthesis from Single Immage
Mar 26, 2019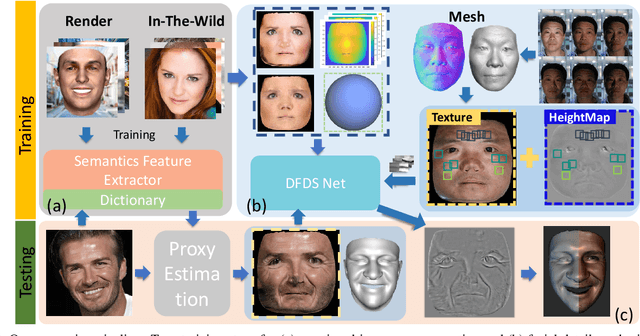

We present a single-image 3D face synthesis technique that can handle challenging facial expressions while recovering fine geometric details. Our technique employs expression analysis for proxy face geometry generation and combines supervised and unsupervised learning for facial detail synthesis. On proxy generation, we conduct emotion prediction to determine a new expression-informed proxy. On detail synthesis, we present a Deep Facial Detail Net (DFDN) based on Conditional Generative Adversarial Net (CGAN) that employs both geometry and appearance loss functions. For geometry, we capture 366 high-quality 3D scans from 122 different subjects under 3 facial expressions. For appearance, we use additional 20K in-the-wild face images and apply image-based rendering to accommodate lighting variations. Comprehensive experiments demonstrate that our framework can produce high-quality 3D faces with realistic details under challenging facial expressions.