 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAIC: Improving Human Action Understanding and Generation with Better Captions for Multi-modal Large Language Models
Paper and Code



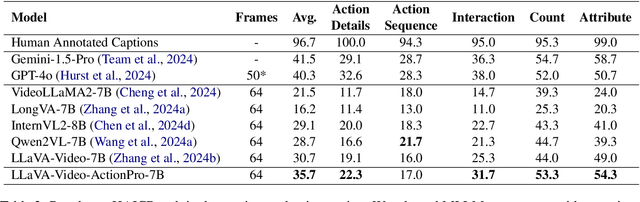
Recent Multi-modal Large Language Models (MLLMs) have made great progress in video understanding. However, their performance on videos involving human actions is still limited by the lack of high-quality data. To address this, we introduce a two-stage data annotation pipeline. First, we design strategies to accumulate videos featuring clear human actions from the Internet. Second, videos are annotated in a standardized caption format that uses human attributes to distinguish individuals and chronologically details their actions and interactions. Through this pipeline, we curate two datasets, namely HAICTrain and HAICBench. \textbf{HAICTrain} comprises 126K video-caption pairs generated by Gemini-Pro and verified for training purposes. Meanwhile, \textbf{HAICBench} includes 500 manually annotated video-caption pairs and 1,400 QA pairs, for a comprehensive evaluation of human action understanding. Experimental results demonstrate that training with HAICTrain not only significantly enhances human understanding abilities across 4 benchmarks, but can also improve text-to-video generation results. Both the HAICTrain and HAICBench are released at https://huggingface.co/datasets/KuaishouHAIC/HAIC.