 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Question Answering Precision with Optimized Vector Retrieval and Instructions
Nov 01, 2024



Question-answering (QA) is an important application of Information Retrieval (IR) and language models, and the latest trend is toward pre-trained large neural networks with embedding parameters. Augmenting QA performances with these LLMs requires intensive computational resources for fine-tuning. We propose an innovative approach to improve QA task performances by integrating optimized vector retrievals and instruction methodologies. Based on retrieval augmentation, the process involves document embedding, vector retrieval, and context construction for optimal QA results. We experiment with different combinations of text segmentation techniques and similarity functions, and analyze their impacts on QA performances. Results show that the model with a small chunk size of 100 without any overlap of the chunks achieves the best result and outperforms the models based on semantic segmentation using sentences. We discuss related QA examples and offer insight into how model performances are improved within the two-stage framework.
Investigating the Synergistic Effects of Dropout and Residual Connections on Language Model Training
Oct 01, 2024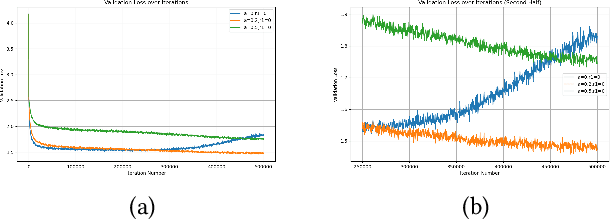
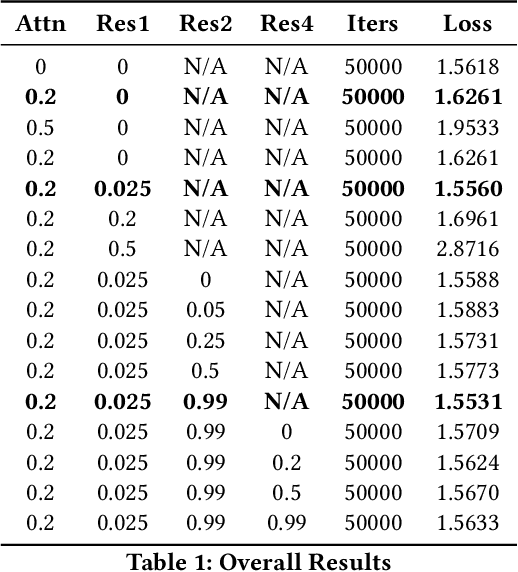
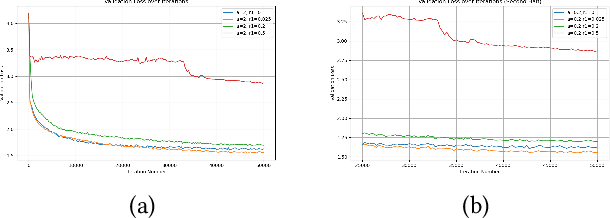
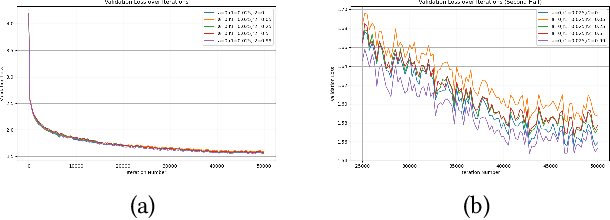
This paper examines the pivotal role of dropout techniques in mitigating overfitting in language model training. It conducts a comprehensive investigation into the influence of variable dropout rates on both individual layers and residual connections within the context of language modeling. Our study conducts training of a decoder implementation on the classic Tiny Shakespeare data to examine the effects of the adjustments on training efficiency and validation error. Results not only confirm the benefits of dropout for regularization and residuals for convergence, but also reveal their interesting interactions. There exists an important trade-off between the depth of residual connections and the dropout on these connections for optimal deep neural network convergence and generalization.