 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-Judge: Reassessing the Performance of LLMs in Extractive QA
Paper and Code

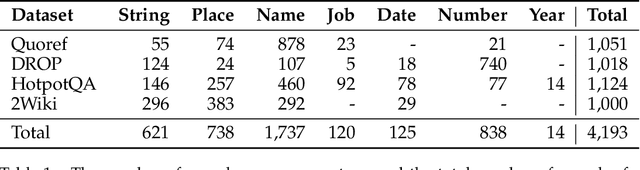
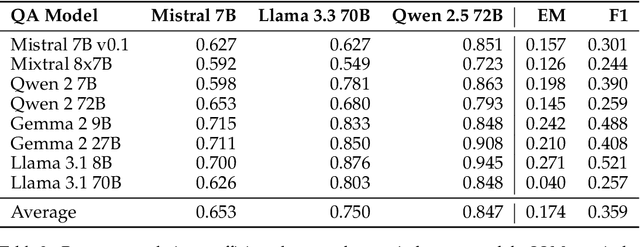
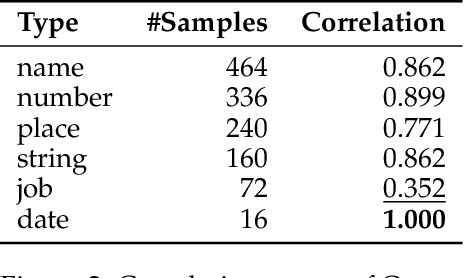
Extractive reading comprehension question answering (QA) datasets are typically evaluated using Exact Match (EM) and F1-score, but these metrics often fail to fully capture model performance. With the success of large language models (LLMs), they have been employed in various tasks, including serving as judges (LLM-as-a-judge). In this paper, we reassess the performance of QA models using LLM-as-a-judge across four reading comprehension QA datasets. We examine different families of LLMs and various answer types to evaluate the effectiveness of LLM-as-a-judge in these tasks. Our results show that LLM-as-a-judge is highly correlated with human judgments and can replace traditional EM/F1 metrics. By using LLM-as-a-judge, the correlation with human judgments improves significantly, from 0.17 (EM) and 0.36 (F1-score) to 0.85. These findings confirm that EM and F1 metrics underestimate the true performance of the QA models. While LLM-as-a-judge is not perfect for more difficult answer types (e.g., job), it still outperforms EM/F1, and we observe no bias issues, such as self-preference, when the same model is used for both the QA and judgment tasks.