 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Feedback Works for Whom? Differential Effects of LLM-Generated Feedback Elements Across Learner Profiles
Feb 12, 2026Large language models (LLMs) show promise for automatically generating feedback in education settings. However, it remains unclear how specific feedback elements, such as tone and information coverage, contribute to learning outcomes and learner acceptance, particularly across learners with different personality traits. In this study, we define six feedback elements and generate feedback for multiple-choice biology questions using GPT-5. We conduct a learning experiment with 321 first-year high school students and evaluate feedback effectiveness using two learning outcomes measures and subjective evaluations across six criteria. We further analyze differences in how feedback acceptance varies across learners based on Big Five personality traits. Our results show that effective feedback elements share common patterns supporting learning outcomes, while learners' subjective preferences differ across personality-based clusters. These findings highlight the importance of selecting and adapting feedback elements according to learners' personality traits when we design LLM-generated feedback, and provide practical implications for personalized feedback design in education.
Are Checklists Really Useful for Automatic Evaluation of Generative Tasks?
Aug 21, 2025Automatic evaluation of generative tasks using large language models faces challenges due to ambiguous criteria. Although automatic checklist generation is a potentially promising approach, its usefulness remains underexplored. We investigate whether checklists should be used for all questions or selectively, generate them using six methods, evaluate their effectiveness across eight model sizes, and identify checklist items that correlate with human evaluations. Through experiments on pairwise comparison and direct scoring tasks, we find that selective checklist use tends to improve evaluation performance in pairwise settings, while its benefits are less consistent in direct scoring. Our analysis also shows that even checklist items with low correlation to human scores often reflect human-written criteria, indicating potential inconsistencies in human evaluation. These findings highlight the need to more clearly define objective evaluation criteria to guide both human and automatic evaluations. \footnote{Our code is available at~https://github.com/momo0817/checklist-effectiveness-study
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
RecMind: Japanese Movie Recommendation Dialogue with Seeker's Internal State
Feb 21, 2024



Humans pay careful attention to the interlocutor's internal state in dialogues. For example, in recommendation dialogues, we make recommendations while estimating the seeker's internal state, such as his/her level of knowledge and interest. Since there are no existing annotated resources for the analysis, we constructed RecMind, a Japanese movie recommendation dialogue dataset with annotations of the seeker's internal state at the entity level. Each entity has a subjective label annotated by the seeker and an objective label annotated by the recommender. RecMind also features engaging dialogues with long seeker's utterances, enabling a detailed analysis of the seeker's internal state. Our analysis based on RecMind reveals that entities that the seeker has no knowledge about but has an interest in contribute to recommendation success. We also propose a response generation framework that explicitly considers the seeker's internal state, utilizing the chain-of-thought prompting. The human evaluation results show that our proposed method outperforms the baseline method in both consistency and the success of recommendations.
Modeling and Utilizing User's Internal State in Movie Recommendation Dialogue
Dec 05, 2020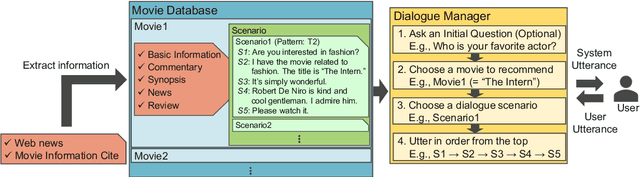



Intelligent dialogue systems are expected as a new interface between humans and machines. Such an intelligent dialogue system should estimate the user's internal state (UIS) in dialogues and change its response appropriately according to the estimation result. In this paper, we model the UIS in dialogues, taking movie recommendation dialogues as examples, and construct a dialogue system that changes its response based on the UIS. Based on the dialogue data analysis, we model the UIS as three elements: knowledge, interest, and engagement. We train the UIS estimators on a dialogue corpus with the modeled UIS's annotations. The estimators achieved high estimation accuracy. We also design response change rules that change the system's responses according to each UIS. We confirmed that response changes using the result of the UIS estimators improved the system utterances' naturalness in both dialogue-wise evaluation and utterance-wise evaluation.
A System for Worldwide COVID-19 Information Aggregation
Jul 28, 2020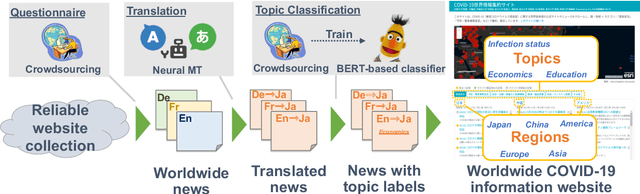

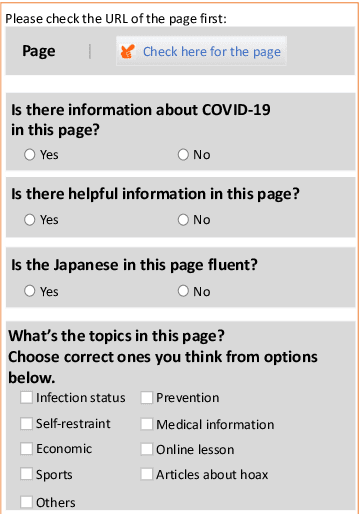
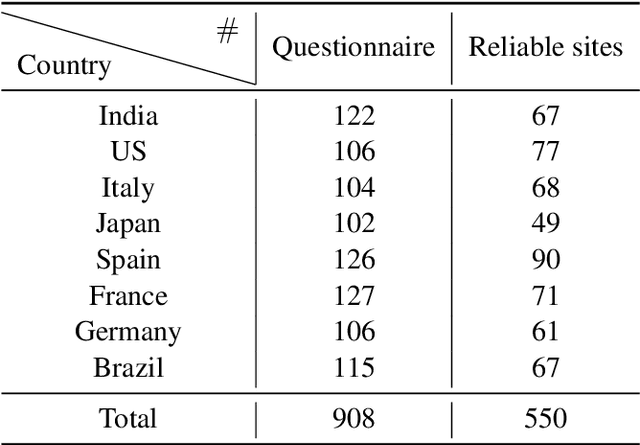
The global pandemic of COVID-19 has made the public pay close attention to related news, covering various domains, such as sanitation, treatment, and effects on education. Meanwhile, the COVID-19 condition is very different among the countries (e.g., policies and development of the epidemic), and thus citizens would be interested in news in foreign countries. We build a system for worldwide COVID-19 information aggregation (http://lotus.kuee.kyoto-u.ac.jp/NLPforCOVID-19 ) containing reliable articles from 10 regions in 7 languages sorted by topics for Japanese citizens. Our reliable COVID-19 related website dataset collected through crowdsourcing ensures the quality of the articles. A neural machine translation module translates articles in other languages into Japanese. A BERT-based topic-classifier trained on an article-topic pair dataset helps users find their interested information efficiently by putting articles into different categories.