 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJaMIE: A Pipeline Japanese Medical Information Extraction System
Nov 08, 2021

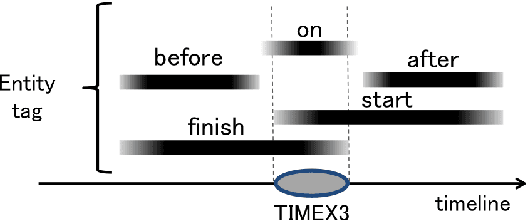
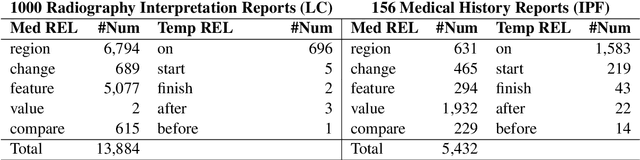
We present an open-access natural language processing toolkit for Japanese medical information extraction. We first propose a novel relation annotation schema for investigating the medical and temporal relations between medical entities in Japanese medical reports. We experiment with the practical annotation scenarios by separately annotating two different types of reports. We design a pipeline system with three components for recognizing medical entities, classifying entity modalities, and extracting relations. The empirical results show accurate analyzing performance and suggest the satisfactory annotation quality, the effective annotation strategy for targeting report types, and the superiority of the latest contextual embedding models.
Modeling and Utilizing User's Internal State in Movie Recommendation Dialogue
Dec 05, 2020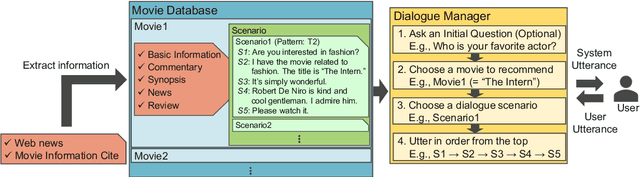



Intelligent dialogue systems are expected as a new interface between humans and machines. Such an intelligent dialogue system should estimate the user's internal state (UIS) in dialogues and change its response appropriately according to the estimation result. In this paper, we model the UIS in dialogues, taking movie recommendation dialogues as examples, and construct a dialogue system that changes its response based on the UIS. Based on the dialogue data analysis, we model the UIS as three elements: knowledge, interest, and engagement. We train the UIS estimators on a dialogue corpus with the modeled UIS's annotations. The estimators achieved high estimation accuracy. We also design response change rules that change the system's responses according to each UIS. We confirmed that response changes using the result of the UIS estimators improved the system utterances' naturalness in both dialogue-wise evaluation and utterance-wise evaluation.
A System for Worldwide COVID-19 Information Aggregation
Jul 28, 2020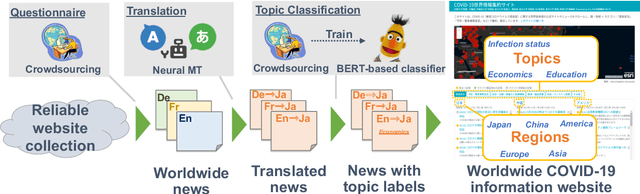

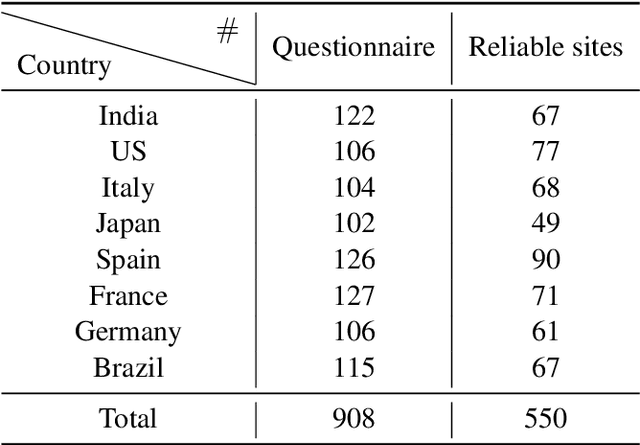
The global pandemic of COVID-19 has made the public pay close attention to related news, covering various domains, such as sanitation, treatment, and effects on education. Meanwhile, the COVID-19 condition is very different among the countries (e.g., policies and development of the epidemic), and thus citizens would be interested in news in foreign countries. We build a system for worldwide COVID-19 information aggregation (http://lotus.kuee.kyoto-u.ac.jp/NLPforCOVID-19 ) containing reliable articles from 10 regions in 7 languages sorted by topics for Japanese citizens. Our reliable COVID-19 related website dataset collected through crowdsourcing ensures the quality of the articles. A neural machine translation module translates articles in other languages into Japanese. A BERT-based topic-classifier trained on an article-topic pair dataset helps users find their interested information efficiently by putting articles into different categories.
FAQ Retrieval using Query-Question Similarity and BERT-Based Query-Answer Relevance
May 24, 2019
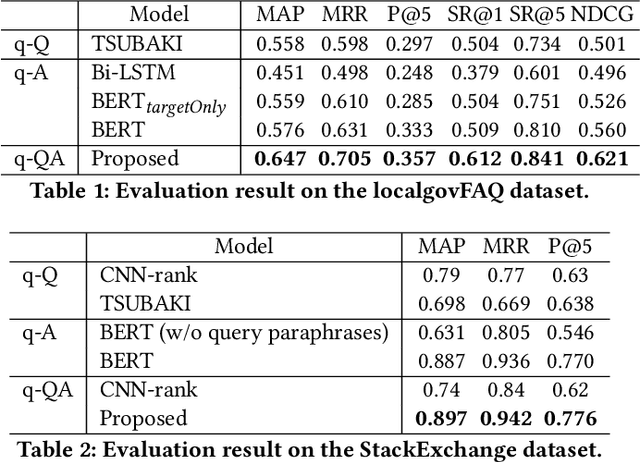


Frequently Asked Question (FAQ) retrieval is an important task where the objective is to retrieve an appropriate Question-Answer (QA) pair from a database based on a user's query. We propose a FAQ retrieval system that considers the similarity between a user's query and a question as well as the relevance between the query and an answer. Although a common approach to FAQ retrieval is to construct labeled data for training, it takes annotation costs. Therefore, we use a traditional unsupervised information retrieval system to calculate the similarity between the query and question. On the other hand, the relevance between the query and answer can be learned by using QA pairs in a FAQ database. The recently-proposed BERT model is used for the relevance calculation. Since the number of QA pairs in FAQ page is not enough to train a model, we cope with this issue by leveraging FAQ sets that are similar to the one in question. We evaluate our approach on two datasets. The first one is localgovFAQ, a dataset we construct in a Japanese administrative municipality domain. The second is StackExchange dataset, which is the public dataset in English. We demonstrate that our proposed method outperforms baseline methods on these datasets.