 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse and Non-redundant Answer Set Extraction on Community QA based on DPPs
Nov 18, 2020
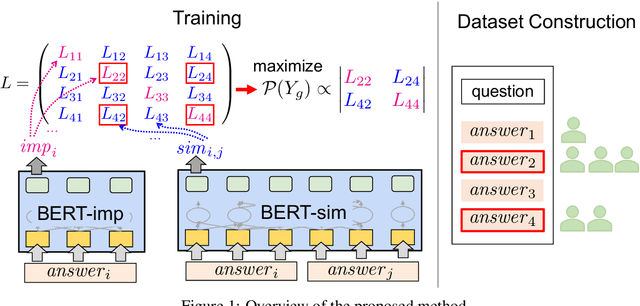

In community-based question answering (CQA) platforms, it takes time for a user to get useful information from among many answers. Although one solution is an answer ranking method, the user still needs to read through the top-ranked answers carefully. This paper proposes a new task of selecting a diverse and non-redundant answer set rather than ranking the answers. Our method is based on determinantal point processes (DPPs), and it calculates the answer importance and similarity between answers by using BERT. We built a dataset focusing on a Japanese CQA site, and the experiments on this dataset demonstrated that the proposed method outperformed several baseline methods.
FAQ Retrieval using Query-Question Similarity and BERT-Based Query-Answer Relevance
May 24, 2019
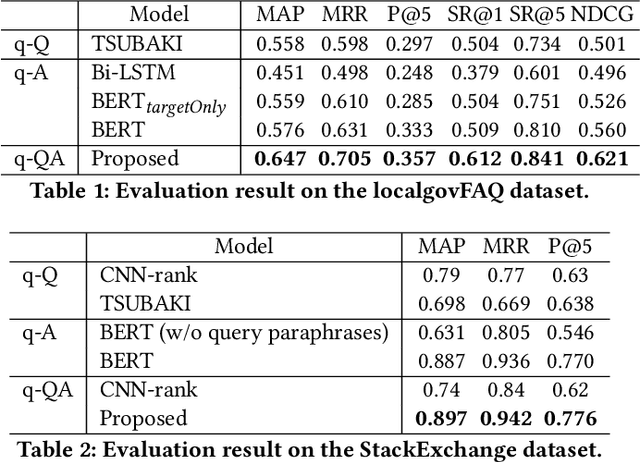


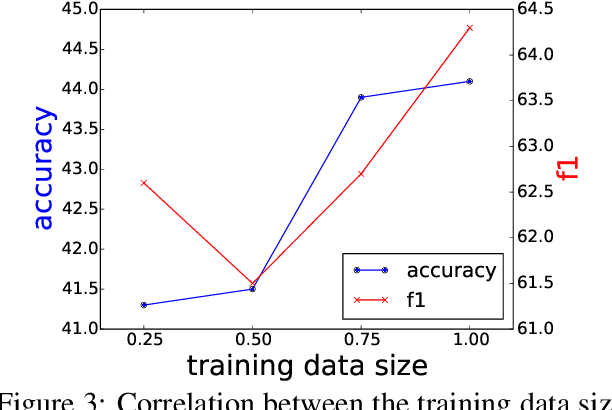
Frequently Asked Question (FAQ) retrieval is an important task where the objective is to retrieve an appropriate Question-Answer (QA) pair from a database based on a user's query. We propose a FAQ retrieval system that considers the similarity between a user's query and a question as well as the relevance between the query and an answer. Although a common approach to FAQ retrieval is to construct labeled data for training, it takes annotation costs. Therefore, we use a traditional unsupervised information retrieval system to calculate the similarity between the query and question. On the other hand, the relevance between the query and answer can be learned by using QA pairs in a FAQ database. The recently-proposed BERT model is used for the relevance calculation. Since the number of QA pairs in FAQ page is not enough to train a model, we cope with this issue by leveraging FAQ sets that are similar to the one in question. We evaluate our approach on two datasets. The first one is localgovFAQ, a dataset we construct in a Japanese administrative municipality domain. The second is StackExchange dataset, which is the public dataset in English. We demonstrate that our proposed method outperforms baseline methods on these datasets.
Reading Comprehension using Entity-based Memory Network
Feb 01, 2017



This paper introduces a novel neural network model for question answering, the \emph{entity-based memory network}. It enhances neural networks' ability of representing and calculating information over a long period by keeping records of entities contained in text. The core component is a memory pool which comprises entities' states. These entities' states are continuously updated according to the input text. Questions with regard to the input text are used to search the memory pool for related entities and answers are further predicted based on the states of retrieved entities. Compared with previous memory network models, the proposed model is capable of handling fine-grained information and more sophisticated relations based on entities. We formulated several different tasks as question answering problems and tested the proposed model. Experiments reported satisfying results.