 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamics in Linear VAE: Posterior Collapse Threshold, Superfluous Latent Space Pitfalls, and Speedup with KL Annealing
Paper and Code
Oct 24, 2023


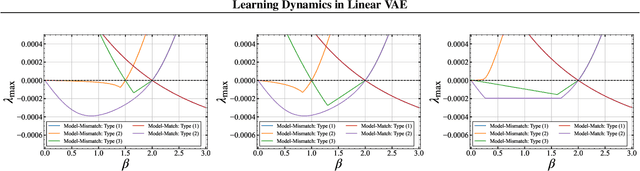
Variational autoencoders (VAEs) face a notorious problem wherein the variational posterior often aligns closely with the prior, a phenomenon known as posterior collapse, which hinders the quality of representation learning. To mitigate this problem, an adjustable hyperparameter $\beta$ and a strategy for annealing this parameter, called KL annealing, are proposed. This study presents a theoretical analysis of the learning dynamics in a minimal VAE. It is rigorously proved that the dynamics converge to a deterministic process within the limit of large input dimensions, thereby enabling a detailed dynamical analysis of the generalization error. Furthermore, the analysis shows that the VAE initially learns entangled representations and gradually acquires disentangled representations. A fixed-point analysis of the deterministic process reveals that when $\beta$ exceeds a certain threshold, posterior collapse becomes inevitable regardless of the learning period. Additionally, the superfluous latent variables for the data-generative factors lead to overfitting of the background noise; this adversely affects both generalization and learning convergence. The analysis further unveiled that appropriately tuned KL annealing can accelerate convergence.